- Compilador
-
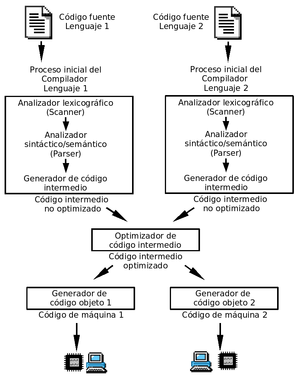 Diagrama a bloques de la operación de un buen compilador.
Diagrama a bloques de la operación de un buen compilador.
Un compilador es un programa informático que traduce un programa escrito en un lenguaje de programación a otro lenguaje de programación, generando un programa equivalente que la máquina será capaz de interpretar. Usualmente el segundo lenguaje es lenguaje de máquina, pero también puede ser un código intermedio (bytecode), o simplemente texto. Este proceso de traducción se conoce como compilación.[1]
Un compilador es un programa que permite traducir el código fuente de un programa en lenguaje de alto nivel, a otro lenguaje de nivel inferior (típicamente lenguaje de máquina). De esta manera un programador puede diseñar un programa en un lenguaje mucho más cercano a como piensa un ser humano, para luego compilarlo a un programa más manejable por una computadora.
Contenido
Partes de un compilador
La construcción de un compilador involucra la división del proceso en una serie de fases que variará con su complejidad. Generalmente estas fases se agrupan en dos tareas: el análisis del programa fuente y la síntesis del programa objeto.
- Análisis: Se trata de la comprobación de la corrección del programa fuente, e incluye las fases correspondientes al Análisis Léxico (que consiste en la descomposición del programa fuente en componentes léxicos), Análisis Sintáctico (agrupación de los componentes léxicos en frases gramaticales ) y Análisis Semántico (comprobación de la validez semántica de las sentencias aceptadas en la fase de Análisis Sintáctico).
- Síntesis: Su objetivo es la generación de la salida expresada en el lenguaje objeto y suele estar formado por una o varias combinaciones de fases de Generación de Código (normalmente se trata de código intermedio o de código objeto) y de Optimización de Código (en las que se busca obtener un código lo más eficiente posible).
Alternativamente, las fases descritas para las tareas de análisis y síntesis se pueden agrupar en Front-end y Back-end:
- Front-end: es la parte que analiza el código fuente, comprueba su validez, genera el árbol de derivación y rellena los valores de la tabla de símbolos. Esta parte suele ser independiente de la plataforma o sistema para el cual se vaya a compilar, y está compuesta por las fases comprendidas entre el Análisis Léxico y la Generación de Código Intermedio.
- Back-end: es la parte que genera el código máquina, específico de una plataforma, a partir de los resultados de la fase de análisis, realizada por el Front End.
Esta división permite que el mismo Back End se utilice para generar el código máquina de varios lenguajes de programación distintos y que el mismo Front End que sirve para analizar el código fuente de un lenguaje de programación concreto sirva para generar código máquina en varias plataformas distintas. Suele incluir la generación y optimización del código dependiente de la máquina.
El código que genera el Back End normalmente no se puede ejecutar directamente, sino que necesita ser enlazado por un programa enlazador (linker)
Historia
En 1946 se desarrolló la primera computadora digital. En un principio, estas máquinas ejecutaban instrucciones consistentes en códigos numéricos que señalaban a los circuitos de la máquina los estados correspondientes a cada operación, lo que se denominó lenguaje máquina.
Pronto los primeros usuarios de estos ordenadores descubrieron la ventaja de escribir sus programas mediante claves más fáciles de recordar que esos códigos; al final, todas esas claves juntas se traducían manualmente a lenguaje máquina. Estas claves constituyen los llamados lenguajes ensambladores.
Pese a todo, el lenguaje ensamblador seguía siendo el de una máquina, pero más fácil de manejar. Los trabajos de investigación se orientaron hacia la creación de un lenguaje que expresara las distintas acciones a realizar de una manera lo más sencilla posible para una persona. El primer compilador fue escrito por Grace Hopper, en 1952 para el lenguaje de programación A-0, En 1950 John Backus dirigió una investigación en IBM sobre un lenguaje algebraico. En 1954 se empezó a desarrollar un lenguaje que permitía escribir fórmulas matemáticas de manera traducible por un ordenador; le llamaron FORTRAN (FORmulae TRANslator). Fue el primer lenguaje de alto nivel y se introdujo en 1957 para el uso de la computadora IBM modelo 704.
Surgió así por primera vez el concepto de un traductor como un programa que traducía un lenguaje a otro lenguaje. En el caso particular de que el lenguaje a traducir es un lenguaje de alto nivel y el lenguaje traducido de bajo nivel, se emplea el término compilador.
La tarea de realizar un compilador no fue fácil. El primer compilador de FORTRAN tardó 18 años-persona en realizarse y era muy sencillo. Este desarrollo de FORTRAN estaba muy influenciado por la máquina objeto en la que iba a ser implementado. Como un ejemplo de ello tenemos el hecho de que los espacios en blanco fuesen ignorados, debido a que el periférico que se utilizaba como entrada de programas (una lectora de tarjetas perforadas) no contaba correctamente los espacios en blanco.
El primer compilador autocontenido, es decir, capaz de compilar su propio código fuente fue el creado para Lisp por Hart y Levin en el MIT en 1962. Desde 1970 se ha convertido en una práctica común escribir el compilador en el mismo lenguaje que este compila, aunque Pascal y C han sido alternativas muy usadas.
Crear un compilador autocontenido genera un problema llamado bootstrapping, es decir el primer compilador creado para un lenguaje tiene que o bien ser compilado por un compilador escrito en otro lenguaje o bien compilado al ejecutar el compilador en un intérprete.
Tipos de compiladores
Esta taxonomía de los tipos de compiladores no es excluyente, por lo que puede haber compiladores que se adscriban a varias categorías:
- Compiladores cruzados: generan código para un sistema distinto del que están funcionando.
- Compiladores optimizadores: realizan cambios en el código para mejorar su eficiencia, pero manteniendo la funcionalidad del programa original.
- Compiladores de una sola pasada: generan el código máquina a partir de una única lectura del código fuente.
- Compiladores de varias pasadas: necesitan leer el código fuente varias veces antes de poder producir el código máquina.
- Compiladores JIT (Just In Time): forman parte de un intérprete y compilan partes del código según se necesitan.
Pauta de creación de un compilador: En las primeras épocas de la informática, el software de los compiladores era considerado como uno de los más complejos existentes.
Los primeros compiladores se realizaron programándolos directamente en lenguaje máquina o en ensamblador. Una vez que se dispone de un compilador, se pueden escribir nuevas versiones del compilador (u otros compiladores distintos) en el lenguaje que compila ese compilador.
Actualmente existen herramientas que facilitan la tarea de escribir compiladores ó intérpretes informáticos. Estas herramientas permiten generar el esqueleto del analizador sintáctico a partir de una definición formal del lenguaje de partida, especificada normalmente mediante una gramática formal y barata, dejando únicamente al programador del compilador la tarea de programar las acciones semánticas asociadas.
Proceso de compilación
Es el proceso por el cual se traducen las instrucciones escritas en un determinado lenguaje de programación a lenguaje máquina. Además de un traductor, se pueden necesitar otros programas para crear un programa objeto ejecutable. Un programa fuente se puede dividir en módulos almacenados en archivos distintos. La tarea de reunir el programa fuente a menudo se confía a un programa distinto, llamado preprocesador. El preprocesador también puede expandir abreviaturas, llamadas a macros, a proposiciones del lenguaje fuente.
Normalmente la creación de un programa ejecutable (un típico.exe para Microsoft Windows o DOS) conlleva dos pasos. El primer paso se llama compilación (propiamente dicho) y traduce el código fuente escrito en un lenguaje de programación almacenado en un archivo a código en bajo nivel (normalmente en código objeto, no directamente a lenguaje máquina). El segundo paso se llama enlazado en el cual se enlaza el código de bajo nivel generado de todos los ficheros y subprogramas que se han mandado compilar y se añade el código de las funciones que hay en las bibliotecas del compilador para que el ejecutable pueda comunicarse directamente con el sistema operativo, traduciendo así finalmente el código objeto a código máquina, y generando un módulo ejecutable.
Estos dos pasos se pueden hacer por separado, almacenando el resultado de la fase de compilación en archivos objetos (un típico.obj para Microsoft Windows, DOS o para Unix); para enlazarlos en fases posteriores, o crear directamente el ejecutable; con lo que la fase de compilación se almacena sólo temporalmente. Un programa podría tener partes escritas en varios lenguajes (por ejemplo C, C++ y Asm), que se podrían compilar de forma independiente y luego enlazar juntas para formar un único módulo ejecutable.
Etapas del proceso
El proceso de traducción se compone internamente de varias etapas o fases, que realizan distintas operaciones lógicas. Es útil pensar en estas fases como en piezas separadas dentro del traductor, y pueden en realidad escribirse como operaciones codificadas separadamente aunque en la práctica a menudo se integren juntas.
Fase de análisis
Análisis léxico
El análisis léxico constituye la primera fase, aquí se lee el programa fuente de izquierda a derecha y se agrupa en componentes léxicos (tokens), que son secuencias de caracteres que tienen un significado. Además, todos los espacios en blanco, líneas en blanco, comentarios y demás información innecesaria se elimina del programa fuente. También se comprueba que los símbolos del lenguaje (palabras clave, operadores,...) se han escrito correctamente.
Como la tarea que realiza el analizador léxico es un caso especial de coincidencia de patrones, se necesitan los métodos de especificación y reconocimiento de patrones, se usan principalmente los autómatas finitos que acepten expresiones regulares. Sin embargo, un analizador léxico también es la parte del traductor que maneja la entrada del código fuente, y puesto que esta entrada a menudo involucra un importante gasto de tiempo, el analizador léxico debe funcionar de manera tan eficiente como sea posible.
Análisis sintáctico
En esta fase los caracteres o componentes léxicos se agrupan jerárquicamente en frases gramaticales que el compilador utiliza para sintetizar la salida. Se comprueba si lo obtenido de la fase anterior es sintácticamente correcto (obedece a la gramática del lenguaje). Por lo general, las frases gramaticales del programa fuente se representan mediante un árbol de análisis sintáctico.
La estructura jerárquica de un programa normalmente se expresa utilizando reglas recursivas. Por ejemplo, se pueden dar las siguientes reglas como parte de la definición de expresiones:
- Cualquier identificador es una expresión.
- Cualquier número es una expresión.
- Si expresión1 y expresión2 son expresiones, entonces también lo son:
- expresión1 + expresión2
- expresión1 * expresión2
- ( expresión1 )
Las reglas 1 y 2 son reglas básicas (no recursivas), en tanto que la regla 3 define expresiones en función de operadores aplicados a otras expresiones.
La división entre análisis léxico y análisis sintáctico es algo arbitraria. Un factor para determinar la división es si una construcción del lenguaje fuente es inherentemente recursiva o no. Las construcciones léxicas no requieren recursión, mientras que las construcciones sintácticas suelen requerirla. No se requiere recursión para reconocer los identificadores, que suelen ser cadenas de letras y dígitos que comienzan con una letra. Normalmente, se reconocen los identificadores por el simple examen del flujo de entrada, esperando hasta encontrar un carácter que no sea ni letra ni dígito, y agrupando después todas las letras y dígitos encontrados hasta ese punto en un componente léxico llamado identificador. Por otra parte, esta clase de análisis no es suficientemente poderoso para analizar expresiones o proposiciones. Por ejemplo, no podemos emparejar de manera apropiada los paréntesis de las expresiones, o las palabras begin y end en proposiciones sin imponer alguna clase de estructura jerárquica o de anidamiento a la entrada.
Análisis semántico
La fase de análisis semántico revisa el programa fuente para tratar de encontrar errores semánticos y reúne la información sobre los tipos para la fase posterior de generación de código. En ella se utiliza la estructura jerárquica determinada por la fase de análisis sintáctico para identificar los operadores y operandos de expresiones y proposiciones.
Un componente importante del análisis semántico es la verificación de tipos. Aquí, el compilador verifica si cada operador tiene operandos permitidos por la especificación del lenguaje fuente. Por ejemplo, las definiciones de muchos lenguajes de programación requieren que el compilador indique un error cada vez que se use un número real como índice de una matriz. Sin embargo, la especificación del lenguaje puede imponer restricciones a los operandos, por ejemplo, cuando un operador aritmético binario se aplica a un número entero y a un número real. Revisa que los arreglos tengan definido el tamaño correcto.
Fase de síntesis
Consiste en generar el código objeto equivalente al programa fuente. Sólo se genera código objeto cuando el programa fuente está libre de errores de análisis, lo cual no quiere decir que el programa se ejecute correctamente, ya que un programa puede tener errores de concepto o expresiones mal calculadas. Por lo general el código objeto es código de máquina relocalizable o código ensamblador. Las posiciones de memoria se seleccionan para cada una de las variables usadas por el programa. Después, cada una de las instrucciones intermedias se traduce a una secuencia de instrucciones de máquina que ejecuta la misma tarea. Un aspecto decisivo es la asignación de variables a registros.
Generación de código intermedio
Después de los análisis sintáctico y semántico, algunos compiladores generan una representación intermedia explícita del programa fuente. Se puede considerar esta representación intermedia como un programa para una máquina abstracta. Esta representación intermedia debe tener dos propiedades importantes; debe ser fácil de producir y fácil de traducir al programa objeto.
La representación intermedia puede tener diversas formas. Existe una forma intermedia llamada "código de tres direcciones" que es como el lenguaje ensamblador de una máquina en la que cada posición de memoria puede actuar como un registro. El código de tres direcciones consiste en una secuencia de instrucciones, cada una de las cuales tiene como máximo tres operandos. Esta representación intermedia tiene varias propiedades:
- Primera.- Cada instrucción de tres direcciones tiene a lo sumo un operador, además de la asignación, por tanto, cuando se generan estas instrucciones, el traductor tiene que decidir el orden en que deben efectuarse las operaciones.
- Segunda.- El traductor debe generar un nombre temporal para guardar los valores calculados por cada instrucción.
- Tercera.- Algunas instrucciones de "tres direcciones" tienen menos de tres operandos, por ejemplo, la asignación.
Optimización de código
La fase de optimización de código consiste en mejorar el código intermedio, de modo que resulte un código máquina más rápido de ejecutar. Esta fase de la etapa de síntesis es posible sobre todo si el traductor es un compilador (difícilmente un interprete puede optimizar el código objeto). Hay mucha variación en la cantidad de optimización de código que ejecutan los distintos compiladores. En los que hacen mucha optimización, llamados "compiladores optimizadores", una parte significativa del tiempo del compilador se ocupa en esta fase. Sin embargo, hay optimizaciones sencillas que mejoran sensiblemente el tiempo de ejecución del programa objeto sin retardar demasiado la compilación.
Estructura de datos principales
La interacción entre los algoritmos utilizados por las fases del compilador y las estructuras de datos que soportan estas fases es, naturalmente, muy fuerte. El escritor del compilador se esfuerza por implementar estos algoritmos de una manera tan eficaz como sea posible, sin aumentar demasiado la complejidad. De manera ideal, un compilador debería poder compilar un programa en un tiempo proporcional al tamaño del mismo.
Componentes léxicos o tokens
Cuando un analizador léxico reúne los caracteres en un token, generalmente representa el token de manera simbólica, es decir, como un valor de un tipo de datos enumerado que representa el conjunto de tokens del lenguaje fuente. En ocasiones también es necesario mantener la cadena de caracteres misma u otra información derivada de ella, tal como el nombre asociado con un token identificador o el valor de un token de número.
En la mayoría de los lenguajes el analizador léxico sólo necesita generar un token a la vez. En este caso se puede utilizar una variable global simple para mantener la información del token. En otros casos (cuyo ejemplo más notable es FORTRAN), puede ser necesario un arreglo (o vector) de tokens.
Árbol sintáctico
Si el analizador sintáctico genera un árbol sintáctico, por lo regular se construye como una estructura estándar basada en un puntero que se asigna de manera dinámica a medida que se efectúa el análisis sintáctico. El árbol entero puede entonces conservarse como una variable simple que apunta al nodo raíz. Cada nodo en la estructura es un registro cuyos campos representan la información recolectada tanto por el analizador sintáctico como, posteriormente, por el analizador semántico. Por ejemplo, el tipo de datos de una expresión puede conservarse como un campo en el nodo del árbol sintáctico para la expresión.
En ocasiones, para ahorrar espacio, estos campos se asignan de manera dinámica, o se almacenan en otras estructuras de datos, tales como la tabla de símbolos, que permiten una asignación y desasignación selectivas. En realidad, cada nodo del árbol sintáctico por sí mismo puede requerir de atributos diferentes para ser almacenado, de acuerdo con la clase de estructura del lenguaje que represente. En este caso, cada nodo en el árbol sintáctico puede estar representado por un registro variable, con cada clase de nodo conteniendo solamente la información necesaria para ese caso.
Tabla de símbolos
Esta estructura de datos mantiene la información asociada con los identificadores: funciones, variables, constantes y tipos de datos. La tabla de símbolos interactúa con casi todas las fases del compilador: el analizador léxico, el analizador sintáctico o el analizador semántico pueden introducir identificadores dentro de la tabla; el analizador semántico agregará tipos de datos y otra información; y las fases de optimización y generación de código utilizarán la información proporcionada por la tabla de símbolos para efectuar selecciones apropiadas de código objeto.
Puesto que la tabla de símbolos tendrá solicitudes de acceso con tanta frecuencia, las operaciones de inserción, eliminación y acceso necesitan ser eficientes, preferiblemente operaciones de tiempo constante. Una estructura de datos estándar para este propósito es la tabla de dispersión o de cálculo de dirección, aunque también se pueden utilizar diversas estructuras de árbol. En ocasiones se utilizan varias tablas y se mantienen en una lista o pila.
Tabla de literales
La búsqueda y la inserción rápida son esenciales también para la tabla de literales, la cual almacena constantes y cadenas utilizadas en el programa. Sin embargo, una tabla de literales necesita impedir las eliminaciones porque sus datos se aplican globalmente al programa y una constante o cadena aparecerá sólo una vez en esta tabla. La tabla de literales es importante en la reducción del tamaño de un programa en la memoria al permitir la reutilización de constantes y cadenas. También es necesaria para que el generador de código construya direcciones simbólicas para las literales y para introducir definiciones de datos en el archivo de código objeto.
Código intermedio
De acuerdo con la clase de código intermedio (por ejemplo, código de tres direcciones o código P) y de las clases de optimizaciones realizadas, este código puede conservarse como un arreglo de cadenas de texto, un archivo de texto temporal o bien una lista de estructuras ligadas. En los compiladores que realizan optimizaciones complejas debe ponerse particular atención a la selección de representaciones que permitan una fácil reorganización.
- Generación de código intermedio
Después de los análisis sintáctico y semántico, algunos compiladores generan una representación intermedia explícita del programa fuente. Se puede considerar esta representación intermedia como un programa para una máquina abstracta. Esta representación intermedia debe tener dos propiedades importantes; debe ser fácil de producir y fácil de traducir al programa objeto.
La representación intermedia puede tener diversas formas. Existe una forma intermedia llamada "código de tres direcciones", que es como el lenguaje ensamblador para una máquina en la que cada posición de memoria puede actuar como un registro. El código de tres direcciones consiste en una secuencia de instrucciones, cada una de las cuales tiene como máximo tres operandos. El programa fuente de (1) puede aparecer en código de tres direcciones como
temp1 := entarea1(60) temp2 := id3 * temp1 (2) temp3 := id2 + temp2 id1 := temp3
Esta representación intermedia tiene varias propiedades. Primera, cada instrucción de tres direcciones tiene a lo sumo un operador, además de la asignación. Por tanto, cuando se generan esas instrucciones el compilador tiene que decidir el orden en que deben efectuarse, las operaciones; la multiplicación precede a la adición al programa fuente de. Segunda, el compilador debe generar un nombre temporal para guardar los valores calculados por cada instrucción. Tercera, algunas instrucciones de "tres direcciones" tienen menos de tres operadores, por ejemplo la primera y la última instrucciones de.
- Optimización de Código
La fase de optimización de código trata de mejorar el código intermedio de modo que resulte un código de máquina más rápido de ejecutar. Algunas optimizaciones son triviales. Por ejemplo, un algoritmo natural genera el código intermedio (2) utilizando una instrucción para cada operador de la representación del árbol después del análisis semántico, aunque hay una forma mejor de realizar los mismos cálculos usando las dos instrucciones
Temp1 := id3 * 60.0 (3) Id1 := id2 + temp1
Este sencillo algoritmo no tiene nada de malo, puesto que el problema se puede solucionar en la fase de optimización de código. Esto es, el compilador puede deducir que la conversión de 60 de entero a real se puede hacer de una vez por todas en el momento de la compilación, de modo que la operación entreal se puede eliminar. Además, temp3 se usa sólo una vez, para transmitir su valor a id1. Entonces resulta seguro sustituir a id1 por temp3, a partir de lo cual la última proposición de (2) no se necesita y se obtiene el código de (3).
Hay muchas variaciones en la cantidad de optimización de código que ejecutan los distintos compiladores. En lo que hacen mucha optimización llamados "compiladores optimizadores", una parte significativa del tiempo del compilador se ocupa en esta fase. Sin embargo hay optimizaciones sencillas que mejoran significativamente del tiempo del compilador se ocupa en esta fase. Sin embargo, hay optimizaciones sencillas que mejoran sensiblemente el tiempo de ejecución del programa objeto sin retardar demasiado la compilación.
Archivos temporales
Al principio las computadoras no tenían la suficiente memoria para guardar un programa completo durante la compilación. Este problema se resolvió mediante el uso de archivos temporales para mantener los productos de los pasos intermedios durante la traducción o bien al compilar "al vuelo", es decir, manteniendo sólo la información suficiente de las partes anteriores del programa fuente que permita proceder a la traducción.
Las limitaciones de memoria son ahora un problema mucho menor, y es posible requerir que una unidad de compilación entera se mantenga en memoria, en especial si se dispone de la compilación por separado en el lenguaje. Con todo, los compiladores ocasionalmente encuentran útil generar archivos intermedios durante alguna de las etapas del procesamiento. Algo típico de éstos es la necesidad de direcciones de corrección hacia atrás durante la generación de código.
Véase también
- Lenguaje ensamblador
- Ensamblador
- Desensamblador
- Decompilador
- Intérprete
- Depurador
- Libros Principles of Compiler Design, Compilers: Principles, Techniques, and Tools
Enlaces externos
- Let's Build a Compiler. Tutorial de Jack W. Crenshaw sobre cómo hacer un compilador
- Java a tope: Traductores y Compiladores con Lex/Yacc, JFlex/Cup y JavaCC. Libro básico sobre compiladores
- Compiladores: Principios, Técnicas y Herramientas. Libro completo sobre compiladores
- Procesamiento léxico, sintáctico, gestión T.S., declaraciones y ejecutables. Herramienta interactiva para el estudio de los procesadores de lenguajes.
Referencias
- ↑ Laborda, Javier; Josep Galimany, Rosa María Pena, Antoni Gual (1985). «Software». Biblioteca práctica de la computación. Barcelona: Ediciones Océano-Éxito, S.A..
Categorías:- Compiladores
- Programas de código objeto
Wikimedia foundation. 2010.