- Desambiguación léxica basada en ventana deslizante
-
Desambiguación léxica basada en ventana deslizante
La desambiguación léxica basada en ventana deslizante es un método para desambiguación léxica. La desambiguación léxica asigna la categoría gramatical correcta a cada palabra de un texto.
Un porcentaje importante (típicamente alrededor del 30%, pero dependiendo del idioma) de las palabras en lenguaje natural son palabras a las que, independientemente del contexto, se les puede asignar más de una análisis morfológico. La correcta resolución de este tipo de ambigüedad es crucial en la mayoría de aplicaciones de procesamiento del lenguaje natural. Por ejemplo, en traducción automática, la traducción equivalente de un término puede ser diferente en función de la categoría gramatical de la palabra.
El etiquetador basado en ventana deslizante es un sistema que asigna una categoría gramatical a una palabra, basado en la información que proporciona una ventana de tamaño fijo formada por las palabras alrededor de la palabra que deseamos desambiguar.
Sus siglas en inglés serían SWPoST (Sliding Window Part-of-Speech Tagger).
Sus dos principales ventajas serían:
- se puede entrenar de forma automática, evitando el etiquetado manual de un corpus
- este etiquetador se puede implementar como un autómata de estados finitos (una Máquina de Mealy).
Definición formal
Sea Γ = {γ1,γ2,...,γ|Γ|} el conjunto de etiquetas de la aplicación, es decir, el conjunto de posibles etiquetas que se puede asignar a una palabra, y W = {w1,w2,...} el vocabulario de la aplicación. Sea T : W → Ρ(Γ) una función de análisis morfológico que asigna a cada palabra w su conjunto de posibles etiquetados T(w) ⊆ Γ, que puede ser implementada mediante un lexicón o un analizador morfológico. Sea Σ = {σ1,σ2,..., σ|Σ|} el conjunto de clases de palabras, que en general será una partición de W con la única restricción de que, para toda σ ∈ Σ todas las palabras w Σ σ reciban el mismo conjunto de eiquetados, es decir,, todas las palabras en casa clase de palabra (σ) pertenezcan a la misma clase de ambigüedad. Normalmente se construye Σ de manera que, para palabras con alta frecuencia de aparación, cada clase de palabras contiene una única palabra, mientras que para palabras con poca frecuencia, cada clase de palabras se hace corresponder exactamente con una clase de ambigüedades, lo que permite un excelente funcionamiento con las palabras ambiguas más frecuentes, a la vez que no son necesarios demasiados parámetros para el funcionamiento del etiquetador.
Con estas deficiones se puede plantear el problema del etiquetador léxico de la siguiente forma: dado un texto w[1]w[2]...w[L] ∈ W*, se le asigna a cada palabra w[t] (mediante un lexicon o un analizador morfológico) una clase de palabra T(w[t]) ∈ Σ para obtener un texto etiquetado ambiguamente σ[1]σ[2]...σ[L] ∈ W*. La función del etiquetador léxico es obtener un texto etiquetado γ[1]γ[2]...γ[L] (con γ[t] ∈ T(σ[t])) lo más correcto posible.
Un etiquetador estadístico busca el etiquetado léxico 'más probable' de un texto σ[1]σ[2]...σ[L] etiquetado ambiguamente:
que mediante la fórmula de Bayes se convierte en:
donde p(γ[1]γ[2]...γ[L]) es la probabilidad de un etiquetado en particular (probabilidad sintáctica) y p(σ[1]...σ[L]γ[1]...γ[L]) es la probabilidad de que ese etiquetado sea el correspondiente al texto σ[1]...σ[L] (probabilidad léxica).
En un Modelo de Markov estas probabilidades se aproximan como productos. Las probabilidades sintácticas se modelan mediante un proceso de Markov de primer orden:
donde γ[0] y γ[L+1] son símbolos delimitadores.
Las probabilidades léxicas son independientes del contexto:
Una forma de etiquetado es aproximar la primera fórmula de probabilidad:
donde
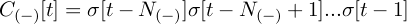 es el 'contexto izquierdo' de tamaño N(-)
es el 'contexto izquierdo' de tamaño N(-)y
es el 'contexto derecho' de tamaño N(+).
De este modo el algoritmo de ventana deslizante sólo tiene en cuenta un contexto de tamaño N(-)+N(+)+1. Para la mayoría de las aplicaciones N(-)=N(+)=1. Por ejemplo para etiquetar la palabra ambigua 'vino' en la frase 'el vino de Alicante', se tendría en cuenta el etiquetado de las palabras 'el' y 'de'.
Véase también
Referencias
- Unsupervised training of a finite-state sliding-window part-of-speech tagger, Enrique Sanchez-Villamil, Mikel L.Forcada y Rafael C. Carrasco
Categorías: Lingüística computacional | Traducción automática
![\gamma^*[1] \ldots \gamma^*[L] = argmax_{\gamma[t] \epsilon T ( \sigma[t] )} p(\gamma[1] \ldots \gamma[L] \sigma[1] \ldots \sigma[L])](/pictures/eswiki/52/44d5d030db236d68ddd32b2efe731044.png)
![\gamma^*[1] \ldots \gamma^*[L] = argmax_{\gamma[t] \epsilon T ( \sigma[t] )} p(\gamma[1] \ldots \gamma[L]) p(\sigma[1] \ldots \sigma[L] \gamma[1] \ldots \gamma[L])](/pictures/eswiki/48/0cf6597a15eaaf8bcbd999e152e39e86.png)
![p(\gamma[1] \gamma[2] \ldots \gamma[L]) = \prod_{t=1}^{t=L} p(\gamma[t+1] \gamma[t])](/pictures/eswiki/51/3876053ea29da5e13dbed48afdf71f90.png)
![p(\sigma[1] \sigma[2] \ldots \sigma[L] \gamma[1] \gamma[2] \ldots \gamma[L]) = \prod_{t=1}^{t=L} p(\sigma[t] \gamma[t])](/pictures/eswiki/54/6ccd2b40c61a02501986c77692685dae.png)
![p(\sigma[1] \sigma[2] \ldots \sigma[L] \gamma[1] \gamma[2] \ldots \gamma[L]) = \prod_{t=1}^{t=L} p(\gamma[t] C_{(-)}[t] \sigma[t] C_{(+)}[t])](/pictures/eswiki/52/4f4f9cbbb30243e145663457615c4702.png)
Wikimedia foundation. 2010.