- Ley Mu
-
El algoritmo Ley μ (μ-law o mu-law) es un sistema de cuantificación logarítmica de una señal de audio. Es utilizado principalmente para audio de voz humana dado que explota las características de ésta. El nombre de Ley μ proviene de µ-law, que usa la letra griega µ. Su aplicación cubre el campo de comunicaciones telefónicas. Este sistema de codificación es usado en Estados Unidos y Japón. En Europa se utiliza un sistema muy parecido llamado ley A.
Contenido
Características básicas de la Ley μ
- Es un algoritmo estandarizado, definido en el estándar ITU-T G.711
- Tiene una complejidad baja
- Utilizado en aplicaciones de voz humana
- No introduce prácticamente retardo algorítmico (dada su baja complejidad)
- Es adecuado para sistemas de transmisión TDM
- No es adecuado para la transmisión por paquetes
- Factor de compresión aproximadamente de 2:1
Digitalmente, el algoritmo ley μ es un sistema de compresión con pérdida en comparación con la codificación lineal normal. Esto significa que al recuperar la señal, ésta no será exactamente igual a la original.
Planteamiento del algoritmo
Este algoritmo se utiliza principalmente para la codificación de voz humana, ya que su funcionamiento explota las características de esta. Las señales de voz están formadas en gran parte por amplitudes pequeñas, ya que son las más importantes para la percepción del habla, por lo tanto estas son muy probables. En cambio, las amplitudes grandes no aparecen tanto, por lo tanto tiene una probabilidad de aparición muy baja.
En el caso de que una señal de audio tuviera una probabilidad de aparición de todos los niveles de amplitud por igual, la cuantificación ideal sería la uniforme, pero en el caso de la voz humana esto no ocurre, estadísticamente aparecen con mucha más frecuencia niveles bajos de amplitud.
El algoritmo Ley Mu explota el factor de que los altos niveles de amplitud no necesitan tanta resolución como los bajos. Por lo tanto, si damos más niveles de cuantificación a las bajas amplitudes y menos a las altas conseguiremos más resolución, un error de cuantificación inferior y por lo tanto una relación señal/ruido (SNR) superior que si efectuáramos directamente una cuantificación uniforme para todos los niveles de la señal.
Esto provoca que si para un determinada SNR necesitamos por ejemplo 16 bits usando una cuantificación uniforme, para la misma SNR usando la codificación Ley μ necesitamos 8 bits, dado que el error de cuantificación es menor y podemos permitirnos usar menos bits para obtener la misma SNR.
Funcionamiento
El algoritmo Ley Mu basa su funcionamiento en un proceso de compresión y expansión llamado compansión. Se aplica una compresión/expansión de las amplitudes y posteriormente una cuantificación uniforme. Las amplitudes de la señal de audio pequeñas son expandidas y las amplitudes más elevadas son comprimidas.
Esto se puede entender de la siguiente forma; cuando una señal pasa a través de un compander, el intervalo de las amplitudes pequeñas de entrada es representado en un intervalo más largo en la salida, y el intervalo de las amplitudes más elevadas pasa a ser representado en un intervalo más pequeño en la salida. En la siguiente figura podemos verlo con claridad:
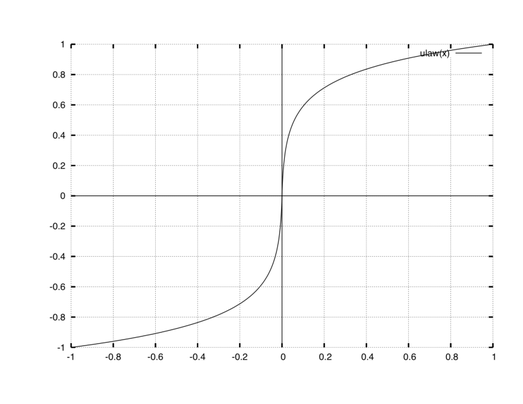
Esta figura muestra que el rango de los valores de entrada (línea horizontal) contenidos en el intervalo [-0.2,0.2] (amplitudes pequeñas) están representados en la salida (línea vertical) en el intervalo [-0.6,0.6]. Podemos comprobar que hay una expansión.
Por otra parte vemos que los valores de entrada contenidos en el intervalo [-1,-0,6] y [0.6,1] son representados en la salida en los intervalos [-0.9,-1] y [0.9,1]. Podemos comprobar que se produce una compresión.
Digitalmente, todo este esquema es equivalente a aplicar una cuantificación no uniforme (logarítmica) a la señal original, donde tendremos pequeños pasos de cuantificación para los valores pequeños de amplitud y pasos de cuantificación grandes para los valores grandes de amplitud. Para recuperar la señal en el destino tendremos que aplicar la función inversa.
Por lo tanto, la implementación del sistema consiste en aplicar a la señal de entrada una función logarítmica y una vez procesada realizar una cuantificación uniforme. Es lo mismo que decir que el paso de cuantificación sigue una función del tipo logarítmico.
Esta función viene definida de la siguiente forma:

La letra μ indica el factor de compresión usado (μ = 255).
Si μ = 0 la entrada es igual a la salida.
Conclusión
Como conclusión podemos decir que al aplicar la cuantificación uniforme a la salida de la transformación logarítmica conseguiremos más niveles de cuantificación para los valores pequeños de la amplitud de la señal de voz, y por lo tanto, más resolución, ya que estos eran los más frecuentes según la distribución de probabilidad de la voz. Esto nos permitirá usar menos bits que una cuantificación uniforme pura obteniendo la misma SNR en los dos casos.
Véase también
Wikimedia foundation. 2010.