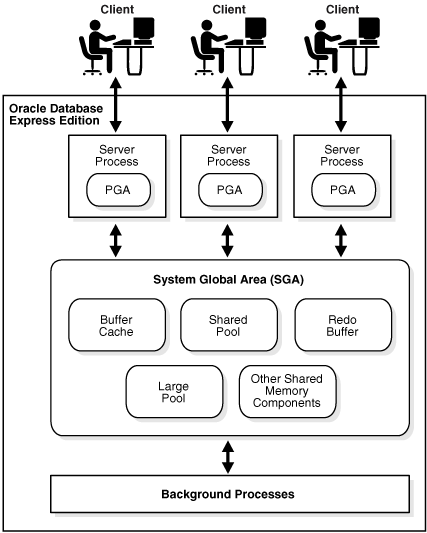
- Área Global del Sistema
-
SGA (Área Global del Sistema) es una estructura básica de memoria de Oracle que sirve para facilitar la transferencia de información entre usuarios y también almacena la información estructural de la BD más frecuentemente requerida.
El área global del sistema y un conjunto de procesos de la base de datos constituyen una instancia de una base de datos Oracle. La base de datos Oracle automáticamente reserva memoria para el área global del sistema cuando se inicia una instancia, y el sistema operativo reclama la memoria cuando se apaga dicha instancia. Cada instancia tiene su propia SGA.
Contenido
¿Que contiene el SGA?
Memoria Oracle (SGA) Su tamaño está determinado por los parámetros:
-
-
- Shared_Pool_Size= Tamaño en bytes del área para SQL compartidos y sentencias PL/SQL.
- Db_Block_Size = Tamaño en bytes de un solo bloque de datos.
- Db_Block_Buffers = Numero de Buffers a localizar en memoria.
- Log_Buffer = Numero de bytes localizados para los Redo Log Buffer.
-
SGA = Shared_Pool_Size + (Db_Block_Size * Db_Block_Buffers) +Log_Buffer.
Está Compuesto por:
-
-
- Los Redo Log Buffers
- Los Database Buffers
- Shared SQL Pool
-
Componentes del SGA
Redo Log Buffer
Es un buffer circular que mantiene todos los cambios que han sido realizados sobre la base de datos por operaciones INSERT, UPDATE, DELETE, CREATE, ALTER y DROP. Las entradas de este buffer contienen toda la información necesaria para reconstruir los cambios realizados a la base de datos por medio de cualquier sentencia del DDL o del DML (el bloque que ha sido cambiado, la posición de cambio y el nuevo valor). El uso del Redo Buffer es estrictamente secuencial, en tal sentido pueden entrelazarse cambios en los bloques de datos producidos por transacciones diferentes. El tamaño de este Buffer también puede ser configurado para mejorar el rendimiento de la instancia y de las aplicaciones que sobre ellas se ejecutan. Los registros Redo describen los cambios realizados en la BD y son escritos en los ficheros redo log para que puedan ser utilizados en las operaciones de recuperación hacia adelante, roll-forward, durante las recuperaciones de la BD. Pero antes de ser escritos en los ficheros redo log son escritos en un caché de la SGA llamado redo log buffer. El servidor escribe periódicamente los registros redo log en los ficheros redo log.
El tamaño del buffer redo log se fija por el parámetro LOG_BUFFER
Buffer Cache (o Database Buffer Cache)
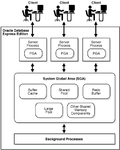 Sga proceso
Sga proceso
Su función es mantener bloques de datos más recientemente leídos directamente de los archivos de datos, esto se hace para un mejor desempeño pues si los datos son de nuevo requeridos por un usuario, su acceso es más rápido.
Cuando se procesa una consulta, el servidor busca los bloques de datos requeridos en esta estructura. Si el bloque no se encuentra en esta estructura, el proceso servidor lee el bloque de la memoria secundaria y coloca una copia en esta estructura. De esta forma, otras peticiones que requieran de este bloque de datos no requerirán de acceso a memoria secundaria (lecturas físicas).Los bloques pueden contener datos modificados que no son permanentemente escritos a disco y los cuales maneja Oracle de una manera consistente para atender la concurrencia de los usuarios conectados a la base de datos, dichos usuarios comparten el acceso a esta área. Los bloques modificados se llamas bloques sucios.
El tamaño de buffer caché se fija por el parámetro DB_BLOCK_BUFFERS del fichero init.ora.
Como el tamaño del buffer suele ser pequeño para almacenar todos los bloques de datos leídos, su gestión se hace mediante el algoritmo LRU.En esta zona se encuentran las sentencias SQL que han sido analizadas. El análisis sintáctico de las sentencias SQL lleva su tiempo y Oracle mantiene las estructuras asociadas a cada sentencia SQL analizada durante el tiempo que pueda para ver si puede reutilizarlas.
Antes de analizar una sentencia SQL, Oracle mira a ver si encuentra otra sentencia exactamente igual en la zona de SQL compartido. Si es así, no la analiza y pasa directamente a ejecutar la que mantiene en memoria. De esta manera se premia la uniformidad en la programación de las aplicaciones. La igualdad se entiende que es lexicográfica, espacios en blanco y variables incluidas.
La base de datos Oracle asigna memoria a la shared pool cuando una nueva instrucción sql se analiza. El tamaño de esta memoria depende de la complejidad de la instrucción. Si toda la shared pool ya ha sido asignada la base de datos Oracle puede liberar elementos de la shared pool hasta que haya suficiente espacio libre para nuevas sentencias. Al liberar un elemento de la shared pool el sql asociado debe ser recompilado y reasignado a otra área de sql compartida la próxima vez que se ejecute.
El contenido de la zona de SQL compartido es:
-
-
- Las sentencias SQL y PL/SQL (texto de la sentencia)
- Plan de ejecución de la sentencia SQL.
- Lista de objetos referenciados.
-
Los pasos de procesamiento de cada petición de análisis de una sentencia SQL son:
-
-
- Comprobar si la sentencia se encuentra en el área compartida.
- Comprobar si los objetos referenciados son los mismos.
- Comprobar si el usuario tiene acceso a los objetos referenciados.Si no, la sentencia es nueva, se analiza y los datos de análisis se almacenan en la zona de SQL compartida.
-
Este caché también se administra mediante el algoritmo LRU. El tamaño del caché está gestionado internamente por el servidor, pero es parte del shared pool.
El tamaño viene determinado por el parámetroSHARED_POOL_SIZE.
Reutilización de memoria en la shared pool:
En general cualquier ítem del área compartida sql o del dictionary row, permanece en la memoria hasta que es descargada. La memoria asignada a elementos que no están siendo utilizados frecuentemente es liberada si acaso es requerida por nuevos elementos que deban ser asignados a un espacio de la shared pool. El algoritmo LRU permite que los elementos compartidos entre varias sesiones permanezcan en memoria tanto tiempo como sean útiles incluso si el proceso que las creó originalmente termina.
Oracle descarga la información contenida en la shared pool por cualquiera de las siguientes razones:
-
-
- Si un objeto del esquema referenciado en una sentencia sql, es modificado posteriormente en cualquier manera, el área del sql compartido es invalidado y la sentencia tendrá que ser recompilada la próxima vez que se ejecute.
- Si se cambia el nombre global de la base de datos, toda la información en en la shared pool es descargada.
- El administrador puede manualmente desalojar toda la información en esta área compartida para evaluar el rendimiento con respecto a ésta área de memoria, que sería esperada luego de que la instancia inicie sin apagar la instancia actual. La sentencia ALTER SYSTEM FLUSH SHARED_POOL es usada para esto.
-
Dividido en:
Library cache
Incluye los espacios comunes de SQL, áreas privadas de SQL (en el caso de una configuración de servidor compartido), los procedimientos PL/SQL y paquetes, y las estructuras de control, tales como bloqueos.
Data Dictionary Cache
También conocido como Dictionary Cache o Row Cache, almacena la información de uso más reciente sobre el diccionario de datos. Es una colección de tablas y vistas que contienen información referente a la base de datos como lo nombres y tipos de datos de las columnas de las tablas, usuarios, passwords y privilegios. Durante la fase de compilación, esta información es necesaria para resolver los nombres de los objetos utilizados en un comando SQL y para validar los privilegios de acceso.
Otros componentes del SGA
Large Pool
El administrador de la base de datos puede configurar esta área de memoria opcional, para proveer localidades más amplias de memoria para:
-
-
- Memoria de sesiones.
- Procesos de I/O del servidor
- Backups de la base de datos y operaciones de recuperación.
-
Al asignar espacios dentro de large pool para un servidor compartido, Oracle puede usar la shared pool principalmente para guardar en caché las sentencias compartidas de sql y evitar la sobrecarga causada por la disminución de la caché de sql compartida. Además la memoria para backup y operaciones de recuperación y para procesos de I/O del servidor es asignada en buffers de algunos cientos de kilobytes, por lo que la large pool mucho más capaz de satisfacer dicha demanda de memoria que la shared pool.
Java Pool
La memoria java pool es usada en la memoria del servidor para todas las sesiones que utilicen código java y datos en la JVM. Esta memoria es usada de diferentes maneras dependiendo del modo en el que la base de datos esté corriendo.
Streams Pool
Esta memoria es usada exclusivamente por flujos de Oracle. Esta almacena colas de mensajes y provee memoria para que los flujos de Oracle capturen procesos y los apliquen. A menos que se configure específicamente, el tamaño de esta memoria empieza en cero. El tamaño de la streams pool crece dinámicamente como sea necesario cuando los flujos de Oracle son usados.
Procesos que acceden al SGA
Procesos de primer plano
- Los procesos de primer plano ejecutan actividades como verificar si un usuario tiene o no permiso de accesar a los datos, generando un plan de ejecución de sentencias para las consultas (querys) enviadas por el usuario y recuperando bloques de datos del buffer caché y modificándolos.
Procesos de primer plano-
-
- Verificación de permisos de usuario
- Elaboración del plan de ejecución para las sentencias
- Recuperación de datos de la caché
- Recuperación en caso de fallos
- Bloqueos
-
Procesos de Segundo plano
- A diferencia de los procesos de primer plano, los procesos de Segundo plano viven desde que la base de datos se inicia hasta que ésta es apagada.
Procesos de segundo plano-
-
- Database Writer
- Log Writer
- Archiver
- Procesos de Checkpoint
-
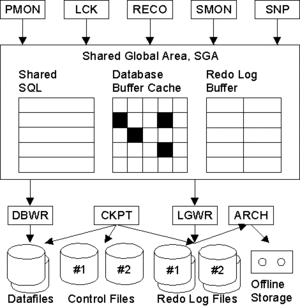
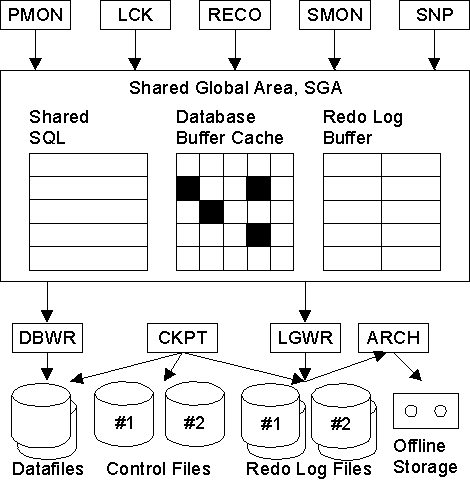
System Monitor, SMON
El SMON es el supervisor del sistema y se encarga de todas las recuperaciones que sean necesarias durante el arranque. Esto puede ser necesario si la BD se paró inesperadamente por fallo físico, lógico u otras causas. Este proceso realiza la recuperación de la instancia de BD a partir de los ficheros redo log. Además límpia los segmentos temporales no utilizados y compacta los huecos libres contiguos en los ficheros de datos. Este proceso se despierta regularmente para comprobar si debe intervenir.
Process Monitor, PMON
Este proceso restaura las transacciones no validadas de los procesos de usuario que abortan, liberando los bloqueos y los recursos de la SGA. Asume la identidad del usuario que ha fallado, liberando todos los recursos de la BD que estuviera utilizando, y anula la transacción cancelada. Este proceso se despierta regularmente para comprobar si su intervención es necesaria.
Database Writer, DBWR
El proceso DBWR es el responsable de gestionar el contenido de los buffers de datos y del caché del diccionario. Él lee los bloques de los ficheros de datos y los almacena en la SGA. Luego escribe en los ficheros de datos los bloques cuyo contenido ha variado. La escritura de los bloques a disco es diferida buscando mejorar la eficiencia de la E/S.Es el único proceso que puede escribir en la BD. Esto asegura la integridad.
Log Writer, LGWR
El proceso LGWR es el encargado de escribir los registros redo log en los ficheros redo log. Los registros redo log siempre contienen el estado más reciente de la BD, ya que puede que el DBWR deba esperar para escribir los bloques modificados desde el buffer de datos a los ficheros de datos.
Checkpoint, CKPT
Este proceso escribe en los ficheros de control los checkpoints. Estos puntos de sincronización son referencias al estado coherente de todos los ficheros de la BD en un instante determinado, en un punto de sincronización. Esto significa que los bloques sucios de la BD se vuelcan a los ficheros de BD, asegurándose de que todos los bloques de datos modificados desde el último checkpoint se escriben realmente en los ficheros de datos y no sólo en los ficheros redo log; y que los ficheros de redo log también almacenan los registros de redo log hasta este instante. La secuencia de puntos de control se almacena en los ficheros de datos, redo log y control.
Archiver, ARCH
El proceso archivador tiene que ver con los ficheros redo log. Por defecto, estos ficheros se reutilizan de manera cíclica de modo que se van perdiendo los registros redo log que tienen una cierta antiguedad. Cuando la BD se ejecuta en modo ARCHIVELOG, antes de reutilizar un fichero redo log realiza una copia del mismo. De esta manera se mantiene una copia de todos los registros redo log por si fueran necesarios para una recuperación. Este es el trabajo del proceso archivador.
Recoverer, RECO El proceso de recuperación está asociado al servidor distribuido. En un servidor distribuido los datos se encuentran repartidos en varias localizaciones físicas, y estas se han de mantener sincronizadas. Cuando una transacción distribuida se lleva a cabo puede que problemas en la red de comunicación haga que una de las localizaciones no aplique las modificaciones debidas. Esta transacción dudosa debe ser resuelta de algún modo, y esa es la tarea del proceso recuperador. Está activo si el parámetro DISTRIBUTED_TRANSACTIONS tiene un valor distinto de 0.
Lock, LCK El proceso de bloqueo está asociado al servidor en paralelo.
Manipulación de los parámetros del SGA
Para asignar un valor a los parámetros.
SQL> ALTER SYSTEM SET <parámetro> = <valor> [SCOPE = <ámbito>]El valor del ámbito puede ser uno de los siguientes.
-
-
- spfile
- memory
- both
-
Para ver el valor actual de un parámetro.
SQL> show parameter <parámetro>
Para mostrar el estado actual del SGA.SQL> show sgaCiclo de vida de una sesión

Ciclo de vida de una sesión:
-
- 1.El programa de usuario manda un mensaje al Puerto especificado en el archive anterior. El listener de oracle recibe el mensaje y crea un proceso dedicado del servidor para procesar las peticiones del usuario.
- 2.El usuario provee sus credenciales, el servidor verifica el diccionario de datos y verifica las credenciales del usuario para ver si este tiene permiso de acceso o no a la base.
- 3.El programa de usuario manda una sentencia sql al servidor dedicado para procesamiento.
- 4.antes de ejecutar la consulta el servidor verifica si hay un plan de ejecucion en el share_sql_pool, si no esta lo elabora y luego lo guarda en la share sql pool; sino solo lo ejecuta
- 5.Antes de llevar a cabo el plan de ejecución verifica los bloques de datos en el database_buffer_cache si no esta ahi va a al disco los toma de ahi y va y los pone en el data buffer cache
- 6.Luego el cliente recibe una respuesta si en dado caso la consulta fue modificada se escribe en el redo log buffer y se actualiza en cache. El cliente se desconecta.
- 7.Los redo log buffer y database_cache se pueden llenar una vez lleno estos se vacian escribiendo lo q esta en el redo_log_buffer en el online redo log y en el datafile lo que esta en el database cache y se da por terminada las transacciones quedando estas ya guardadas en disco.
- 1.El programa de usuario manda un mensaje al Puerto especificado en el archive anterior. El listener de oracle recibe el mensaje y crea un proceso dedicado del servidor para procesar las peticiones del usuario.
Referencias
Fernandez, Iggy (2009). «3» (en Inglés). Beginning Oracle database 11g Administration. Apress. pp. 56-62. ISBN 1-59059-968-3.
Enlaces externos
-
Wikimedia foundation. 2010.