- DVC codificación distribuida de vídeo
-
DVC codificación distribuida de vídeo
- Este artículo trata sobre un sistema de codificación de vídeo. En inglés Distributed Source Coding
Paradigma de codificación que permite reducir la complejidad de los codificadores de vídeo. Este nuevo paradigma ha permitido que los teléfonos móviles de tercera generación o cámaras de vigilancia de circuito cerrado pudieran transmitir vídeo de una manera mucho más eficiente.Hasta ahora la investigación y estandarización de los algoritmos de codificación de vídeo ha adoptado un paradigma donde el codificador es el encargado de explorar la estadística de la fuente, dando lugar a codificadores complejos y decodificadores sencillos. Este paradigma está fuertemente condicionado por aplicaciones como la radiodifusión (broadcasting), el vídeo bajo demanda y el streaming de vídeo. En todos estos casos, los contenidos se generan por uno(o unos pocos) codificadores y se dirigen a un gran número de decodificadores,cuyo coste debe mantenerse reducido para garantizar un acceso económico a los servicios.
Así por ejemplo, los estándares más utilizados de codificación de vídeo como el MPEG-2, MPEG-4, H-263, son cada vez más eficientes gracias a un mejor modelado y explotación de las características estadísticas de la señal de vídeo, pero también resultan más complejos debido a la cantidad de cálculos complejos que deben realizar. De esta manera, el conjunto codificador-descodificador (códec) es totalmente asimétrico con codificadores que suelen ser de 5 a 10 veces más complejos que los decodificadores
Contenido
Datos generales
La codificación distribuida de vídeo responde a unas nuevas necesidades como son las cámaras de vigilancia de baja potencia, las cámaras inalámbricas por PC o las cámaras de teléfonos móviles. En estas arquitecturas es importante tener un bajo consumo de potencia tanto en el codificador como en el decodificador. Esto requiere disponer de un codificador de bajo coste y baja complejidad mientras que el decodificador puede ser más complejo y costoso.
En cambio la codificación de vídeo tradicional se basan en la aplicación de una transformada matemática (eliminación de la redundancia espacial) y en la aplicación de la estimación y compensación del movimiento (eliminación de la redundancia temporal). Esta codificación supone una gran complejidad en el codificador del orden de 5 a 10 veces más complejo que el descodificador. De tal manera que el codificador es el máximo responsable en lograr el máximo ratio de compresión mientras que el decodificador se limita a ejecutar las órdenes dictadas por el codificador. Este tipos de codificación funciona de manera muy eficiente cuando el vídeo es codificado una sola vez y en cambio va a ser decodificado muchos más veces. Este es el caso del vídeo bajo demanda.
Características
La codificación de vídeo se basa en dos resultados derivados de la Teoría de la Información: los teoremas de Slepian-Wolf y de Wyner-Ziv. Estos teoremas proponen que en la codificación de dos o más secuencias aleatorias,dependientes una de la otra, son codificadas de una manera independiente. Un único descodificador intenta explotar las dependencias existentes entre los dos flujos originales. Esta codificación nos permito desplazar la complejidad del codificador al descodificador.
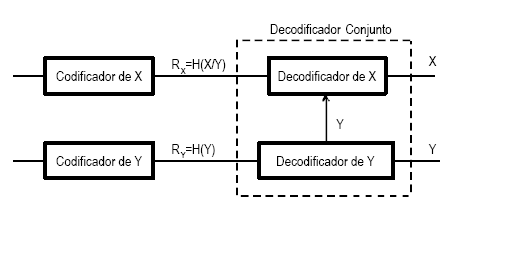 Figura 2.Codificación de dos fuentes estadísticaente dependientes
Figura 2.Codificación de dos fuentes estadísticaente dependientes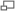
Antecedentes
En los años setenta se formularon dos teoremas de Slepian–Wolf y Wyner-Ziv que permitían codificar dos señales estadísticamente independientes de una manera distribuida (codificación separada, decodificación conjunta) utilizando un flujo de transmisión parecida a los sistemas tradicionales de codificación de vídeo. El teorema de Slepian–Wolf también se conoce como codificación distribuida sin pérdidas. Y el teorema de Wyner-Ziv se conoce como codificación distribuida con pérdidas.
Dos fuentes X e Y, estadísticamente dependientes y codificadas de forma conjunta, la transmisión sin pérdidas puede realizarse a una tasa binaria R igual o superior a su entropía conjunta H(X,Y).
El Teorema de Slepian-Wolf establece que la transmisión de X e Y, con una probabilidad de error cercana a cero puede realizarse a una tasa H(X,Y) cuando ambas fuentes se codifican separadamente pero se decodifican conjuntamente.
Un codificador que explota este hecho recibe el nombre de codificador de Slepian-Wolf (SWC – del inglés Slepian Wolf Coder). En concreto, si X e Y se codifican con tasas RX e RY respectivamente, entonces la transmisión con una probabilidad de error cercana a cero puede realizarse si RX ³ H(X/Y), RY³ H(Y/X) y RX + RY³ H(X,Y) (ver Figura 3). Evidentemente, el caso óptimo consiste en realizar la codificación en aquellas tasas (RX,RY) en las que RX +RY es H(X,Y) (límites de Slepian-Wolf).
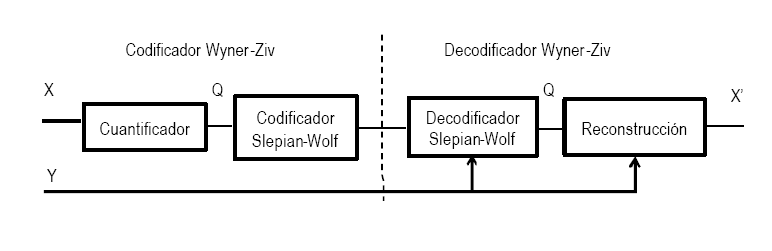 Figura 3.Diagrama de bloques de un codificador Wyner-Ziv
Figura 3.Diagrama de bloques de un codificador Wyner-ZivPor ejemplo, la señal Y (llamada información lateral) puede transmitirse primero a una tasa RY = H(Y) mientras que la señal X (llamada señal principal) puede transmitirse después a una tasa RX = H(X/Y), ya que Y estará en el decodificador y podrá ser utilizada en la decodificación (Figura 4).
 Figura 4.Region de tasas que se pueden conseguir
Figura 4.Region de tasas que se pueden conseguirLos teoremas Slepian-Wolf y Wyner-Ziv no describen el diseño constructivo de códigos que permitan una codificación de fuente óptima o aproximadamente óptima desde el punto de vista tasa-distorsión. De hecho, el paradigma de codificación que proponen estos teoremas no ha sido explotado desde un punto de vista práctico, hasta muy recientemente con la aparición de aplicaciones y escenarios en los que resulta necesario realizar una codificación de baja complejidad.
Implementación
Dentro de la Codificación Distribuida de Vídeo hay dos modelos propuestos por dos facultades americanas que son la referencia y a partir de los cuales se parte en los diferentes proyectos versados en este tema; los modelos propuestos por Girod (Stanford)y Ramchamdran (Berkeleley). En el siguiente diagrama se muestra el modelo standford.
Modelo Stanford
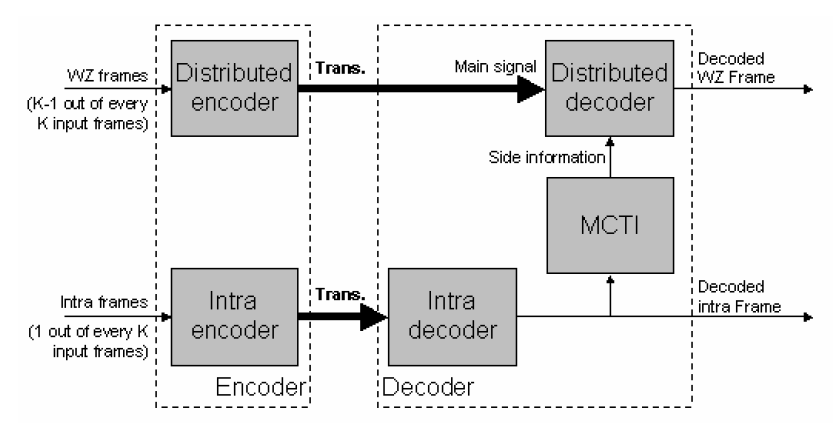 Figura 5.Modelo Stanford
Figura 5.Modelo StanfordEl modelo Stanford basado en técnicas de codificación de canal. La idea es tratar la información lateral (Y) como una versión ruidosa de la señal principal (X). Entonces Y debe ser enviada usando una codificación convencional (Intraframe) mientras que X es enviada a una tasa menor que su entropía.
Modelo Berkeley
El Modelo Berkeley basado en técnicas de codificación mediante síndromes, se desarrollaron dos arquitecturas:
- DISCUSS (DIstributed Source Coding Using Syndromes).
- PRISM (Power-efficient Robust hIgh-compression Syndrome-based Multimedia coding).
En 2002 se hizo una propuesta PRISM para transmisión multimedia sobre redes inalámbricas. La solución que proponía era combinar una baja complejidad de codificación utilizando la codificación interframe. El resultado fue que todavía estaba por debajo de la eficiencia de compresión de otros estándares de codificación tradicional.
Modelos actuales
El mismo año haciendo uso de turbo codecs para la codificación del canal, añadiendo la transformada DCT y añadiendo información adicional para ayudar al decodificador a mejorar la estimación del movimiento se consiguió unos resultados muy parecidos a los estándares de codificación tradicional.
El año 2005 el Instituto Superior Técnico (IST) de Lisboa se desarrolló un otra propuesta de DVC basada en turbo codecs.
El proyecto europeo DISCOVER está formado por un grupo de universidades. Su objetivo es valorar y explotar todas las posibilidades que ofrece el DVC para así especificar arquitecturas que se puedan integrar en sistemas de comunicaciones.
Aplicaciones
La codificación distribuida de vídeo es apropiada en todas aquellas aplicaciones en las que los terminales que deban realizar la codificación tengan restricciones significativas con respecto a la energía disponible, la capacidad computacional o su coste.
Dentro de este conjunto de aplicaciones podríamos hacer una distinción entre entornos monocámara (monoview) y multicámara (multiview), es decir, entornos en los cuáles usamos una cámara y por tanto hay un solo codificador o entornos en los que el decodificador recibe información procedente de varias cámaras.
Los sistemas de comunicación que implementan este paradigma de codificación abarcan un amplio abanico de aplicaciones como son las cámaras de vigilancia (circuito cerrado),sensores de red o videoconferencia.
Aplicaciones prácticas que se están desarrollando actualmente:
- Sistemas de imagen multivista. En aquellas aplicaciones de vídeovigilancia en las que se requiere información visual de un determinado escenario con gran fidelidad, suelen utilizarse redes de cámaras situadas en posiciones precisas que permiten obtener imágenes del escenario desde distintos ángulos. El conocimiento de la posición y parámetros de las cámaras permite una renderización de la información visual de la escena, pudiendo dar lugar a representaciones de gran calidad. Aunque entre las diversas imágenes captadas puede existir una gran correlación espacial, ésta no puede ser utilizada por los codificadores puesto que las cámaras no suelen poder comunicarse entre ellas. En estas aplicaciones, es aconsejable que la correlación que hay entre las imágenes captadas se explote en el decodificador, tal y como propone la DVC. Además, el uso de DVC reduce el coste del sistema mediante el abaratamiento de la red de cámaras.
- Transmisión de vídeo en comunicaciones móviles. El valor de los dispositivos móviles inalámbricos está íntimamente relacionado con la duración de la batería, por lo que las aplicaciones que hacen uso de estos dispositivos tienen que limitar el consumo de energía y consecuentemente, la complejidad computacional.
- Redes de vídeosensores para vigilancia. Las redes de cámaras de vídeo utilizadas para la vigilancia de edificios, autopistas, aeropuertos, etc., suelen integrar un gran número de cámaras. Recientemente, el uso de cámaras inalámbricas en estas aplicaciones está recibiendo un gran interés ya que gracias a las conexiones inalámbricas, las cámaras pueden se pueden instalar en casi cualquier sitio sin necesidad de una infraestructura cara de cableado que proporcione energía y capacidad de comunicación a las cámaras. Como en cualquier red de sensores inalámbricos, las señales captadas se deben comprimir para reducir la anchura de banda de transmisión. Además, los algoritmos de compresión también consumen energía del sensor, especialmente si es complejo. En este escenario, los algoritmos DVC pueden conseguir un buen compromiso entre la ganancia de energía debida a la reducción de la cantidad de datos a transmitir y la debida a la menor complejidad de los algoritmos utilizados.
- Cámaras desechables. El uso de cámaras digitales desechables o de muybajo coste resulta de gran interés en aquellas aplicaciones en las que las cámaras se destruyen (como en la filmación de procesos de combustión) o puedan ser dañadas (en la vigilancia de eventos públicos en grandes áreas).En este tipo de aplicaciones, la DVC también es de indudable interés gracias a que el elemento de mayor complejidad y coste, el decodificador, puede utilizarse una y otra vez.
Así pues, resultará fundamental combinar las estrategias de codificación distribuida (con baja complejidad en el codificador) con las convencionales (baja complejidad en el decodificador) para poder obtener sistemas totalmente funcionales.
Així doncs, resultarà fonamental combinar les estratègies de codificació distribuïda (amb baixa complexitat en el codificador) amb les convencionals (baixa complexitat en el decodificador) per a poder obtenir sistemes totalment funcionals.
Futuras líneas de investigación de la codificación de vídeo distribuido
Algunas aplicaciones concretas en las que se prevé que esta tecnología tendrá un fuerte impacto las encontramos en dos escenarios bien definidos: la transmisión de vídeo en comunicaciones móviles y la compresión de señales provenientes de redes de vídeosensores.
En el caso de la codificación distribuida para transmisión de vídeo en redes móviles, se pretende evaluar las prestaciones de estas técnicas teniendo en cuenta las características propias de este escenario (limitación en ancho de banda, adaptación al ancho de banda de canal, robustez ante errores, posibilidad de canales de retorno).
Además, se considera especialmente relevante valorar las posibilidades de análisis de las imágenes que se pueden realizar en las estaciones base con objeto de optimizar el uso de la información lateral. El objetivo es pues introducir métodos de análisis más sofisticados que permitan mejorar los resultados actuales. Además, el análisis de la imagen en el decodificador puede proporcionar información de alto nivel (metadatos) que pueden resultar útiles como valor añadido a los servicios de vídeo en terminales móviles.
En el caso de la codificación distribuida aplicada a la compresión de señales de una red de vídeosensores, el objetivo es el de estudiar la eficacia de este tipo de compresión cuando se consideran todos los tipos de correlaciones existentes (dentro de una misma señal o entre varias señales).
Los algoritmos publicados hasta la fecha, explotan la correlación existente dentro de cada señal de vídeo o la correlación espacial entre varias señales, pero no todas las correlaciones simultáneamente. Evidentemente, el contenido de cada escena o la disposición de las cámaras y de los objetos puede hacer que sólo parte de la correlación temporal o espacial sea útil como información lateral.
Links a otras páginas
proyecto europeo de donde se puede descargar el códec
departamento de investigación de la upc involucrado en el desarrollo del códec
la universidad politécnica de laussana también ha participado en el códec discover
proyecto universidad stanford donde se encuentra el codigo fuente y algorismos del códec LDPC
proyecto universidad berkeley donde se encuentra documentación de su modelo
explica más detalladamente los teoremas de Wyner-Ziv
explica com se está implementando el DVC con otros sistemas de codificació en el 3G
explica el desarrollo de los turbocódecs
Categorías: Tecnología de vídeo y cine | Códecs de vídeo | Telecomunicaciones
Wikimedia foundation. 2010.