- Tabla de dimensión
-
En un almacén de datos o un sistema OLAP, la construcción de Cubos OLAP requiere de una tabla de hechos y varias tablas de dimensiones, éstas acompañan a la tabla de hechos y determinan los parámetros (dimensiones) de los que dependen los hechos registrados en la tabla de hechos.
Contenido
Introducción
En la construcción de cubos OLAP, las tablas de dimensiones son elementos que contienen atributos (o campos) que se utilizan para restringir y agrupar los datos almacenados en una tabla de hechos cuando se realizan consultas sobre dicho datos en un entorno de almacén de datos o data mart.
Estos datos sobre dimensiones son parámetros de los que dependen otros datos que serán objeto de estudio y análisis y que están contenidos en la tabla de hechos. Las tablas de dimensiones ayudan a realizar ese estudio/análisis aportando información sobre los datos de la tabla de hechos, por lo que puede decirse que en un cubo OLAP, la tabla de hechos contiene los datos de interés y las tablas de dimensiones contienen metadatos sobre dichos hechos.
Granularidad de dimensión y jerarquías
Cada dimensión puede referirse a conceptos como 'tiempo', 'productos', 'clientes', 'zona geográfica', etc. Ahora bien, cada dimensión puede estar medida de diferentes maneras según la granularidad deseada, por ejemplo, para la dimensión "zona geográfica" podríamos considerar 'localidades', 'provincias', 'regiones', 'países' o 'continentes'.
 Granularidad de la dimensión Zona geográfica, con una jerarquía de cinco niveles.
Granularidad de la dimensión Zona geográfica, con una jerarquía de cinco niveles.
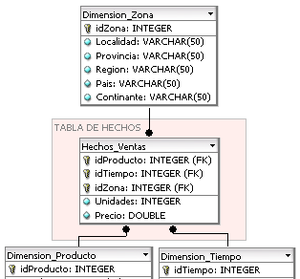 Detalle de una tabla de dimensión de un cubo OLAP con un esquema en estrella.
Detalle de una tabla de dimensión de un cubo OLAP con un esquema en estrella.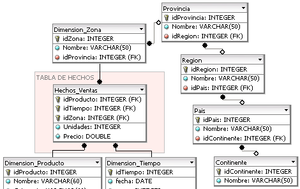 Detalle de una tabla de dimensión de un cubo OLAP con un esquema en copo de nieve.
Detalle de una tabla de dimensión de un cubo OLAP con un esquema en copo de nieve.La unidad de medida (por localidades, provincias, etc.) determinará esa granularidad, cuanto más pequeña sea esta unidad de medida más fina será esta granularidad (grano fino); si las unidades de medida son mayores, entonces hablaremos de granularidad gruesa (grano grueso).
En muchas ocasiones interesa disponer de los datos a varios niveles de granularidad, es decir, es importante para el negocio poder consultar los datos (siguiendo el ejemplo de las zonas) por localidades, provincias, etc., en estos casos se crea una jerarquía con la dimensión, ya que tenemos varios niveles de asociación de los datos (con otras dimensiones como el tiempo, se podrían crear niveles jerárquicos del tipo 'días', 'semanas', 'meses', ...).
Cuando las tablas de dimensión asociadas a una tabla de hechos no reflejan ninguna jerarquía (por ejemplo: Las zonas siempre son 'provincias' y sólo provincias, el tiempo se mide en 'días' y sólo en días, etc.) el cubo resultante tendrá forma de estrella, es decir, una tabla de hechos central rodeada de tantas tablas como dimensiones, y sólo habrá, además de la tabla de hechos, una tabla por cada dimensión.
Cuando una o varias de las dimensiones del cubo refleja algún tipo de jerarquía existen dos planteamientos con respecto a la forma que deben ser diseñadas las tablas de dimensión. El primero consiste en reflejar todos los niveles jerárquicos de una dimensión dentro de una única tabla, en este caso también tendríamos un esquema en estrella como el que se ha descrito anteriormente.
El otro planteamiento consiste en aplicar a las dimensiones las reglas de normalización de las bases de datos relacionales. Estas normas están ideadas para evitar redundancias en los datos aumentando el número de tablas, de esta forma se consigue almacenar la información en menos espacio. Este diseño da como resultado en esquema en copo de nieve. Este modo de organizar las dimensiones de un cubo OLAP tiene un inconveniente respecto al modelo en estrella que no compensa el ahorro de espacio de almacenamiento. En las aplicaciones OLAP el recurso crítico, no es tanto el espacio para almacenamiento como el tiempo de respuesta del sistema ante consultas del usuario, y está constatado que los modelos en copo de nieve tienen un tiempo de respuesta mayor que los modelos en estrella.
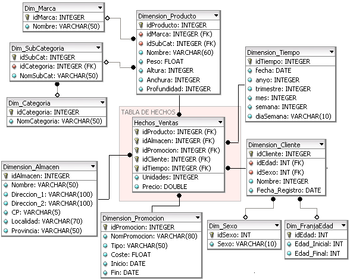
La dimensión "tiempo"
En cualquier Dataware house se pueden encontrar varios cubos con sus tablas de hechos repletas de registros sobre alguna variable de interés para el negocio que debe ser estudiada. Como ya se ha comentado, cada tabla de hechos estará rodeada de varias tablas de dimensiones, según que parámetros sirvan mejor para realizar el análisis de los hechos que se quieren estudiar. Un parámetro que casi con toda probabilidad será común a todos los cubos es el tiempo, ya que lo habitual es almacenar los hechos conforme van ocurriendo a lo largo del tiempo, obteniéndose así una serie temporal de la variable a estudiar.
Tabla de tiempos (1) Fecha (PK) datetime Año char(4) Trimestre char(6) Mes char(10) Tabla de tiempos (2) TiempoID (PK) integer Fecha datetime Año char(4) Trimestre char(6) Mes char(10) Dado que el tiempo es una dimensión presente en prácticamente cualquier cubo de un sistema OLAP merece una atención especial. Al diseñar la dimensión tiempo (tanto para un esquema en estrella como para un esquema en copo de nieve) hay que prestar especial cuidado, ya que puede hacerse de varias maneras y no todas son igualmente eficientes. La forma más común de diseñar esta tabla es poniendo como clave principal (PK) de la tabla la fecha o fecha/hora (tabla de tiempos 1). Este diseño no es de los más recomendables, ya que a la mayoría de los sistemas de gestión de bases de datos les resulta más costoso hacer búsquedas sobre campos de tipo "date" o "datetime", estos costes se reducen si el campo clave es de tipo entero, además, un dato entero siempre ocupa menos espacio que un dato de tipo fecha (el campo clave se repetirá en millones de registros en la tabla de hechos y eso puede ser mucho espacio), por lo que se mejorará el diseño de la tabla de tiempos si se utiliza un campo "TiempoID" de tipo entero como clave principal (tabla de tiempos 2).
A la hora de rellenar la tabla de tiempos, si se ha optado por un campo de tipo entero para la clave, hay dos opciones, la que quizá sea más inmediata consiste en asignar valores numéricos consecutivos (1, 2, 3, 4, ...) para los diferentes valores de fechas. La otra opción consistiría en asignar valeres numéricos del tipo "yyyymmdd", es decir que los cuatro primeros dígitos del valor del campo indican el año de la fecha, los dos siguientes el mes y los dos últimos el día. Este segundo modo aporta una cierta ventaja sobre el anterior, ya que de esta forma se consigue que el dato numérico en sí, aporte por si solo la información de a que fecha se refiere, es decir, si en la tabla de hechos encontramos el valor 20040723, sabremos que se refiere al día 23 de julio de 2004; en cambio, con el primer método, podríamos encontrar valores como 8456456, para saber a que fecha se refiere este valor tendríamos que hacer una consulta sobre la tabla de tiempos.
Además del campo clave TiempoID, la tabla de hechos debe contener otros campos que también es importante estudiar. Estos campos serían:
Tabla de tiempos (3) TiempoID (PK) integer Fecha datetime Año char(4) Trimestre char(6) TrimestreID int Mes char(10) MesID int Quincena char(10) QuincenaID int Semana char(10) SemanaID int Día char(10) DíaID int DíaSemana char(10) DíaSemanaID int - Un campo "año".- Para contener valores como '2002', 2003, '2004', ...
- Un campo "mes".- Aquí se pueden poner los valores 'Enero', 'Febrero', ... (o de forma abreviada: 'Ene', 'Feb', ...), esto no está mal, pero se puede mejorar si el nombre del mes va acompañado con el año al que pertenece, es decir '2004 Enero', '2004 Febrero', ... de esta forma se optimiza la búsqueda de los valores de un mes en concreto, ya que con el primer método, si se buscan los valores pertenecientes al mes de "Enero de 2003", toda esa información está contenida en un sólo campo, el "mes", no haría falta consultar también el campo año.
- Un campo "mesID".- Este campo tendría que ser de tipo entero y serviría para almacenar valores del tipo 200601 (para '2006 Enero') o 200602 (para '2006 Febrero'), de esta forma es posible realizar ordenaciones y agrupaciones por meses.
De forma análoga a como se ha hecho con el campo mes, se podrían añadir más campos como "Época del año", "Trimestre", "Quincena", "Semana" de tipo texto para poder visualizarlos, y sus análogos de tipo entero "Época del año_ID", "TrimestreID", "QuincenaID", "SemanaID" para poder realizar agrupaciones y ordenaciones. En general se puede añadir un campo por cada nivel de granularidad deseado.
Otro campo especial que se puede añadir es el "Día de la semana" ('lunes', 'martes', ...), este campo se suele añadir para poder hacer estudios sobre el comportamiento de los días de la semana en general (no del primer lunes del mes de enero de un año concreto, este tipo de estudio no suele tener interés), por esta razón, este campo no necesita ir acompañado del mes o del año como los campos anteriores. También se puede añadir su campo dual "ID" de tipo entero para poder ordenar y agrupar si fuera necesario.
Con los añadidos descritos podríamos tener una tabla de tiempos como la de la figura "Tabla de tiempos (3)". Esta sería válida para un diseño en estrella, para un diseño en copo de nieve habría que desglosar la tabla de tiempos en tantas tablas como niveles jerárquicos contenga. Obsérvese que los campos de tipo "ID" son todos de tipo entero, ya que será sobre estos campos sobre los que se realizarán la mayoría de las operaciones y estas se realizarán más eficientemente sobre datos enteros.
Referencias
- Darmawikarta, Djoni (2007); Dimensional Data Warehousing with MySQL, Pub. BrainySoftware. ISBN 0-9752128-2-6.
- Kimball, Ralph et al (1998); The Data Warehouse Lifecycle Toolkit, p17. Pub. Wiley. ISBN 0-471-25547-5.
- Kimball, Ralph (1996); The Data Warehouse Toolkit, p. 100. Pub. Wiley. ISBN 0-471-15337-0.
Véase también
- Almacén de datos
- Cubo OLAP
- Esquema en estrella
- Esquema en copo de nieve
- OLAP
- ROLAP
- Tabla de hechos
- Metadato
Enlaces externos
Categorías:- Bases de datos
- Modelos de bases de datos
- Herramientas de gestión




Wikimedia foundation. 2010.