- CUDA
-
CUDA Desarrollador NVIDIA Corporation
Nvidia's CUDA zoneInformación general Última versión estable 2.3
22 de julio de 2009Género GPGPU Sistema operativo Windows 7, Windows Vista, Windows XP, Windows Server 2008, Windows Server 2003, Linux, Mac OS X Licencia Propietaria, Freeware En español ? CUDA son las siglas de Compute Unified Device Architecture (Arquitectura de Dispositivos de Cómputo Unificado) que hace referencia tanto a un compilador como a un conjunto de herramientas de desarrollo creadas por nVidia que permiten a los programadores usar una variación del lenguaje de programación C para codificar algoritmos en GPU de nVidia.
Por medio de wrappers se puede usar Python, Fortran y Java en vez de C/C++ y en el futuro también se añadirá FORTRAN, OpenGL y Direct3D.
Funciona en todas las GPU nVidia de la serie G8X en adelante, incluyendo GeForce, Quadro y la línea Tesla.[1] nVidia afirma que los programas desarrollados para la serie GeForce 8 también funcionarán sin modificaciones en todas las futuras tarjetas nVidia, gracias a la compatibilidad binaria.
CUDA intenta explotar las ventajas de las GPU frente a las CPU de propósito general utilizando el paralelismo que ofrecen sus múltiples núcleos, que permiten el lanzamiento de un altísimo número de hilos simultáneos. Por ello, si una aplicación está diseñada utilizando numerosos hilos que realizan tareas independientes (que es lo que hacen las GPU al procesar gráficos, su tarea natural), una GPU podrá ofrecer un gran rendimiento en campos que podrían ir desde la biología computacional a la criptografía por ejemplo.
El primer SDK se publicó en febrero de 2007 en un principio para Windows, Linux, y más adelante en su versión 2.0 para Mac OS. Actualmente se ofrece para Windows XP/Vista/7, para Linux 32/64 bits y para Mac OS.
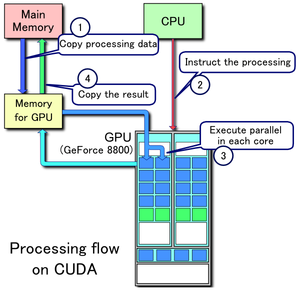 Ejemplo de flujo de procesamiento CUDA
Ejemplo de flujo de procesamiento CUDA
1. Se copian los datos de la memoria principal a la memoria de la GPU
2. La CPU encarga el proceso a la GPU
3. La GPU lo ejecuta en paralelo en cada núcleo
4. Se copia el resultado de la memoria de la GPU a la memoria principalContenido
Ventajas
CUDA presenta ciertas ventajas sobre otros tipos de computación sobre GPU utilizando APIs gráficas.
- Lecturas dispersas: se puede consultar cualquier posición de memoria.
- Memoria compartida: CUDA pone a disposición del programador un área de memoria de 16KB (ó 48KB en la serie Fermi) que se compartirá entre threads. Dado su tamaño y rapidez puede ser utilizada como caché.
- Lecturas más rápidas de y hacia la GPU.
- Soporte para enteros y operadores a nivel de bit.
Limitaciones
- No se puede utilizar recursividad, punteros a funciones, variables estáticas dentro de funciones o funciones con número de parámetros variable
- No está soportado el renderizado de texturas
- En precisión simple no soporta números desnormalizados o NaNs
- Puede existir un cuello de botella entre la CPU y la GPU por los anchos de banda de los buses y sus latencias.
- Los threads, por razones de eficiencia, deben lanzarse en grupos de al menos 32, con miles de hilos en total.
El modelo CUDA
CUDA intenta aprovechar el gran paralelismo, y el alto ancho de banda de la memoria en las GPU en aplicaciones con un gran coste aritmético frente a realizar numerosos accesos a memoria principal, lo que podría actuar de cuello de botella.
El modelo de programación de CUDA está diseñado para que se creen aplicaciones que de forma transparente escalen su paralelismo para poder incrementar el número de núcleos computacionales. Este diseño contiene tres puntos claves, que son la jerarquía de grupos de hilos, las memorias compartidas y las barreras de sincronización.
La estructura que se utiliza en este modelo está definido por un grid, dentro del cual hay bloques de hilos que están formados por como máximo 512 hilos distintos.
Cada hilo está identificado con un identificador único, que se accede con la variable threadIdx. Esta variable es muy útil para repartir el trabajo entre distintos hilos. threadIdx tiene 3 componentes (x, y, z), coincidiendo con las dimensiones de bloques de hilos. Así, cada elemento de una matriz, por ejemplo, lo podría tratar su homólogo en un bloque de hilos de dos dimensiones.
Al igual que los hilos, los bloques se identifican mediante blockIdx (en este caso con dos componentes x e y). Otro parámetro útil es blockDim, para acceder al tamaño de bloque.
Kernel
Un kernel en “C for CUDA”, es una función la cual al ejecutarse lo hará en N distintos hilos en lugar de en secuencial. Se define incluyendo __global__ en la declaración. Por ejemplo:
//Definición del kernel __global__ void f(int a, int b, int c) { }
Si nuestra función f queremos que calcule la diferencia entre dos vectores A y B y lo almacene en un tercero C:
__global__ void f(int* A, int* B, int* C) { int i = threadIdx.x; C[i] = A[i] - B[i]; }
Esta función se ejecutaría una vez en cada hilo, reduciendo el tiempo total de ejecución en gran medida, y dividiendo su complejidad, O(n), por una constante directamente relacionada con el número de procesadores disponibles.
El mismo ejemplo con matrices sería:
__global__ void f(int** A, int** B, int** C) { int i = threadIdx.x; //Columna del bloque que ocupa este determinado hilo int j= threadIdx.y; //Fila C[i][j] = A[i][j] - B[i][j]; }
Invocaciones a un kernel
En una llamada a un kernel, se le ha de pasar el tamaño de grid y de bloque, por ejemplo, en el main del ejemplo anterior podríamos añadir:
dim3 bloque(N,N); //Definimos un bloque de hilos de N*N dim3 grid(M,M) //Grid de tamaño M*M f<<<grid, bloque>>>(A, B, C);
En el momento que se invoque esta función, los bloques de un grid se enumerarán y distribuirán por los distintos multiprocesadores libres.
Sincronización
Como los distintos hilos colaboran entre ellos y pueden compartir datos, se requieren unas directivas de sincronización. En un kernel, se puede explicitar una barrera incluyendo una llamada a __syncthreads(), en la que todos los hilos se esperarán a que los demás lleguen a ese mismo punto.
Jerarquía de memoria
Los hilos en CUDA pueden acceder a distintas memorias, unas compartidas y otras no.
- En primer lugar, está la memoria privada de cada hilo, solamente accesible desde él mismo.
- Cada bloque de hilos posee también un espacio de memoria, compartida en este caso por los hilos del bloque y con un ámbito de vida igual que el del propio bloque.
- Todos los hilos pueden acceder a una memoria global.
Además, existen otros dos espacios de memoria más, que son de solo lectura y accesibles por todos los hilos. Son la memoria constante y la de texturas. Todas las memorias de acceso global persisten mientras esté el kernel en ejecución.
Arquitectura CUDA
Un multiprocesador contiene ocho procesadores escalares, dos unidades especiales para funciones trascendentales, una unidad multihilo de instrucciones y una memoria compartida. El multiprocesador crea y maneja los hilos sin ningún tipo de overhead por la planificación, lo cual unido a una rápida sincronización por barreras y una creación de hilos muy ligera, consigue que se pueda utilizar CUDA en problemas de muy baja granularidad, incluso asignando un hilo a un elemento por ejemplo de una imagen (un píxel).
Tarjetas Soportadas
Nvidia GeForce GeForce GTX 590 GeForce GTX 580 GeForce GTX 570 GeForce GTX 560 GeForce GTX 550 GeForce GTX 480 GeForce GTX 470 GeForce GTX 465 GeForce GTX 460 GeForce GTX 450 GeForce GT 440 GeForce GTX 295 GeForce GTX 285 GeForce GTX 280 GeForce GTX 275 GeForce GTX 260 GeForce GTS 250 GeForce GTS 240 GeForce GT 240 GeForce GT 220 GeForce GT 430 GeForce 210/G210 GeForce 9800 GX2 GeForce 9800 GTX+ GeForce 9800 GTX GeForce 9800 GT GeForce 9600 GSO GeForce 9600 GT GeForce 9500 GT GeForce 9400 GT GeForce 9400 mGPU GeForce 9300 mGPU GeForce 9100 mGPU GeForce 8800 Ultra GeForce 8800 GTX GeForce 8800 GTS GeForce 8800 GT GeForce 8800 GS GeForce 8600 GTS GeForce 8600 GT GeForce 8600 mGT GeForce 8500 GT GeForce 8400 GS GeForce 8300 mGPU GeForce 8200 mGPU GeForce 8100 mGPU Nvidia GeForce Mobile GeForce GTX 480M GeForce GTX 285M GeForce GTX 280M GeForce GTX 260M GeForce GTS 360M GeForce GTS 350M GeForce GTS 260M GeForce GTS 250M GeForce GT 335M GeForce GT 330M GeForce GT 325M GeForce GT 320M GeForce 310M GeForce GT 240M GeForce GT 230M GeForce GT 220M GeForce G210M GeForce GTS 160M GeForce GTS 150M GeForce GT 130M GeForce GT 120M GeForce G110M GeForce G105M GeForce G103M GeForce G102M GeForce G100 GeForce 9800M GTX GeForce 9800M GTS GeForce 9800M GT GeForce 9800M GS GeForce 9700M GTS GeForce 9700M GT GeForce 9650M GT GeForce 9650M GS GeForce 9600M GT GeForce 9600M GS GeForce 9500M GS GeForce 9500M G GeForce 9400M G GeForce 9300M GS GeForce 9300M G GeForce 9200M GS GeForce 9100M G GeForce 8800M GTX GeForce 8800M GTS GeForce 8700M GT GeForce 8600M GT GeForce 8600M GS GeForce 8400M GT GeForce 8400M GS GeForce 8400M G GeForce 8200M G Nvidia Quadro Quadro 6000 Quadro 5000 Quadro 4000 Quadro FX 5800 Quadro FX 5600 Quadro FX 4800 Quadro FX 4700 X2 Quadro FX 4600 Quadro FX 3800 Quadro FX 3700 Quadro FX 1800 Quadro FX 1700 Quadro FX 580 Quadro FX 570 Quadro FX 380 Quadro FX 370 Quadro NVS 450 Quadro NVS 420 Quadro NVS 295 Quadro NVS 290 Quadro Plex 1000 Model IV Quadro Plex 1000 Model S4 Nvidia Quadro Mobile Quadro FX 3800M Quadro FX 3700M Quadro FX 3600M Quadro FX 2800M Quadro FX 2700M Quadro FX 1800M Quadro FX 1700M Quadro FX 1600M Quadro FX 880M Quadro FX 770M Quadro FX 570M Quadro FX 380M Quadro FX 370M Quadro FX 360M Quadro NVS 320M Quadro NVS 160M Quadro NVS 150M Quadro NVS 140M Quadro NVS 135M Quadro NVS 130M Nvidia Tesla Tesla C2050 Tesla S1070 Tesla M1060 Tesla C1060 Tesla C870 Tesla D870 Tesla S870 Referencias
Véase también
Enlaces externos
Wikimedia foundation. 2010.