- Coeficiente de correlación de Spearman
-
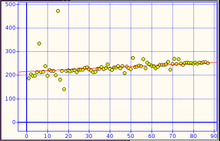 El coeficiente de correlación de Spearman es menos sensible que el de Pearson para los valores muy lejos de lo esperado. En este ejemplo: Pearson = 0.30706 Spearman = 0.76270
El coeficiente de correlación de Spearman es menos sensible que el de Pearson para los valores muy lejos de lo esperado. En este ejemplo: Pearson = 0.30706 Spearman = 0.76270
En estadística, el coeficiente de correlación de Spearman, ρ (ro) es una medida de la correlación (la asociación o interdependencia) entre dos variables aleatorias continuas. Para calcular ρ, los datos son ordenados y reemplazados por su respectivo orden.
El estadístico ρ viene dado por la expresión:
donde D es la diferencia entre los correspondientes estadísticos de orden de x - y. N es el número de parejas.
Se tiene que considerar la existencia de datos idénticos a la hora de ordenarlos, aunque si éstos son pocos, se puede ignorar tal circunstancia
Para muestras mayores de 20 observaciones, podemos utilizar la siguiente aproximación a la distribución t de Student
La interpretación de coeficiente de Spearman es igual que la del coeficiente de correlación de Pearson. Oscila entre -1 y +1, indicándonos asociaciones negativas o positivas respectivamente, 0 cero, significa no correlación pero no independencia. La tau de Kendall es un coeficiente de correlación por rangos, inversiones entre dos ordenaciones de una distribución normal bivariante.Contenido
Ejemplo
Los datos brutos usados en este ejemplo se ven debajo.
CI Horas de TV a la semana 106 7 86 0 100 28 100 50 99 28 103 28 97 20 113 12 113 7 110 17 El primer paso es ordenar los datos de la primera columna. Después, se crean dos columnas más. Ambas son para ordenar (establecer un lugar en la lista) de las dos primeras columnas. Después se crea una columna "d" que muestra las diferencias entre las dos columnas de orden. Finalmente, se crea otra columna "d2". Esta última es sólo la columna "d" al cuadrado.
Después de realizar todo esto con los datos del ejemplo, se debería acabar con algo como lo siguiente:
CI (i) Horas de TV a la semana (t) orden(i) orden(t) d d2 86 0 1 1 0 0 97 20 2 6 4 16 99 28 3 8 5 25 100 50 4.5 10 5.5 30.25 100 28 4.5 8 3.5 12.25 103 28 6 8 2 4 106 7 7 2.5 4.5 20.25 110 17 8 5 3 9 113 7 9.5 2.5 7 49 113 12 9.5 4 5.5 30.25 Nótese como el número de orden de los valores que son idénticos es la media de los números de orden que les corresponderían si no lo fueran.
Los valores de la columna d2 pueden ser sumados para averiguar
 . El valor de n es 10. Así que esos valores pueden ser sustituídos en la fórmula.
. El valor de n es 10. Así que esos valores pueden ser sustituídos en la fórmula.De lo que resulta ρ = − 0.187878787879.
Determinando la significación estadística
La aproximación moderna al problema de averiguar si un valor observado de ρ es significativamente diferente de cero (siempre tendremos -1 ≤ ρ ≤ 1) es calcular la probabilidad de que sea mayor o igual que el ρ esperado, dada la hipótesis nula, utilizando un permutation test. Esta aproximación es casi siempre superior a los métodos tradicionales, a no ser que el data set sea tan grande que la potencia informática no sea suficiente para generar permutaciones (poco probable con la informática moderna), o a no ser que sea difícil crear un algoritmo para crear permutaciones que sean lógicas bajo la hipótesis nula en el caso particular de que se trate (aunque normalmente estos algoritmos no ofrecen dificultad).
Aunque el test de permutación es a menudo trivial para cualquiera con recursos informáticos y experiencia en programación, todavía se usan ampliamente los métodos tradicionales para obtener significación. La aproximación más básica es comparar el ρ observado con tablas publicadas para varios niveles de significación. Es una solución simple si la significación sólo necesita saberse dentro de cierto rango, o ser menor de un determinado valor, mientras haya tablas disponibles que especifiquen los rangos adecuados. Más abajo hay una referencia a una tabla semejante. Sin embargo, generar estas tablas es computacionalmente intensivo y a lo largo de los años se han usado complicados trucos matemáticos para generar tablas para tamaños de muestra cada vez mayores, de modo que no es práctico para la mayoría extender las tablas existentes.
Una aproximación alternativa para tamaños de muestra suficientemente grandes es una aproximación a la distribución t de Student. Para tamaños de muestra más grandes que unos 20 individuos, la variable
tiene una distribución t de Student en el caso nulo (correlación cero). En el caso no nulo (ej: para averiguar si un ρ observado es significativamente diferente a un valor teórico o si dos ρs observados difieren significativamente, los tests son mucho menos potentes, pero puede utilizarse de nuevo la distribución t.
Una generalización del coeficiente de Spearman es útil en la situación en la cual hay tres o más condiciones, varios individuos son observados en cada una de ellas, y predecimos que las observaciones tendrán un orden en particular. Por ejemplo, un conjunto de individuos pueden tener tres oportunidades para intentar cierta tarea, y predecimos que su habilidad mejorará de intento en intento. Un test de la significación de la tendencia entre las condiciones en esta situación fue desarrollado por E. B. Page y normalmente suele conocerse como Page's trend test para alternativas ordenadas.
Véase también
- Regresión lineal
- Cohesión social
- Kendall tau rank correlation coefficient
Enlaces externos
- Tabla de los valores críticos del coeficiente de correlación de Spearman para muestras pequeñas (inglés)
- Calculadora en internet (inglés)
- Otra calculadora en internet (español)
Fuente
Wikipedia. Traducción del inglés.
Categorías:- Contraste de hipótesis
- Estadística no paramétrica
- Covarianza y correlación
- Psicometría



Wikimedia foundation. 2010.