- FAST TCP
-
FAST TCP
FAST TCP (Fast Active queue management Scalable Transmission Control Protocol) es un algoritmo de control de congestión para TCP, diseñado por investigadores del “Californian Institute of Technology” y que últimamente está dando de que hablar por la capacidad que tendría dicho algoritmo de incrementar las velocidades de transferencia en Internet, sin necesidad de modificar la infraestructura actual.
En pocas palabras, actualmente Internet funciona bajo Reno TCP, diseñado en 1988 y que transmite paquetes de 1500 byte, esperando confirmaciones del receptor. Si no hay respuesta, se retransmite un paquete a menor velocidad hasta que llega correctamente. Por el contrario, FAST TCP mide constantemente el tiempo que tardan en llegar los paquetes transmitidos, analizando retrasos y prediciendo la tasa de transferencia que podrá soportar la conexión para que no se produzcan perdidas. Con este sistema, se han llegado a alcanzar en internet velocidades de 100 Gb/s en conexiones transatlánticas.
Contenido
Descripción
Las principales características que diferencian a este algoritmo respecto a Reno TCP son tres:
- Es un algoritmo basado en ecuaciones y por tanto elimina las oscilaciones a nivel de paquete
- Emplea retardo de cola como medida primaria de la congestión, lo cual, como veremos, es más fiable que medir la probabilidad de error.
- Tiene un comportamiento de dinámica de flujo estable y alcanza un equilibrio imparcial que no penaliza flujos largos, como hace el actual algoritmo de control. Es por tanto, asintóticamente estable.
Decimos que el uso del retraso de cola es ventajoso respecto al de la probabilidad de pérdida de paquete por dos principales razones:
Primero, porque la estimación de la primera es más precisa que en la segunda, ya que para sistemas de banda ancha, la pérdida de un paquete es un hecho relativamente raro, y por tanto es complicado estimar un valor correcto. Y aún si se hiciera, la medida o muestreo de las pérdidas de paquete es mucho más ruda, menos fina, que la de retrasos de cola, aunque ambas medidas sean igual de ruidosas. Además, cada medida de pérdida de paquete proporciona un solo bit de información para el filtrado de ruido, mientras que la medida del retardo ofrece información multi-bit.
Segundo, porque basándose en el modelo de TCP/AQM, la dinámica de colas es escalable respecto a la capacidad de la red. La cual cosa da estabilidad al algoritmo frente a los futuros aumentos de capacidad en las conexiones.
Habría que decir que TCP Reno, desde su aparición, ha soportado un incremento de Internet de seis órdenes de magnitud a nivel de tamaño, velocidad, carga y conectividad. Pero es sabido que a medida que aumente el ancho de banda, TCP Reno se convertirá finalmente en un cuello de botella para sí mismo.
Existen dos formas de enfocar el diseño de un algoritmo de control de congestión: a nivel de flujo y a nivel de paquete. Reno TCP fue diseñado enfocando el problema a nivel de paquete, y los resultados que se obtuvieron a nivel de flujo fueron una consecuencia, pero no un objetivo. En FAST TCP (al igual que en HSTCP y STCP), basándonos en el diseño a nivel de flujo, obtenemos ciertos resultados a nivel de paquete.
Arquitectura
Este mecanismo de control de congestión tiene cuatro componentes: data control, window control, burstiness control y estimatión. Todos ellos son funcionalmente independientes, de forma que pueden ser diseñados por separado e incluso mejorados por separado. En pocas palabras, el componente de data control determina “qué” paquetes transmitir, window control determina “cuantos” y burstiness control determina “cuando”. Estas decisiones se basan en la información que contiene la estimación. El componente window control trabaja a niveles de tiempo del tamaño del RTT, mientras que el burstiness control trabaja a escalas más pequeñas.
A continuación se describe con más detalle cada componente:
- Estimation: de la transmisión de cada paquete obtiene información “feedback” de dos componentes: una sobre el retraso de colas (multi bit) y otra que indica si se ha perdido o no el paquete (1 solo bit). Cuando se recibe un ACK positivo, FAST calcula el RTT para el correspondiente paquete de datos, e inmediatamente calcula el mínimo RTT y una media exponencial del RTT, que serán usadas en el componente “window control”. Si se recebe un ACK negativo, genera una indicación de pérdida sobre este paquete de datos al “data control”
- Window control: como hemos comentado ya, FAST TCP emplea el retardo de cola (como TCP Vegas) como parámetro principal en el ajuste de la ventana. Bajo condiciones normales de la red, FAST actualiza periódicamente la ventana de congestión w de acuerdo con:
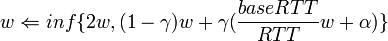
donde γ es una constante entre 0 y 1, RTT es la media actual de round-trip time, baseRTT es el valor mínimo de RTT hasta el momento y es un parámetro que controla la imparcialidad del protocolo.
Aunque los tamaños de ventana se ajustan de forma distinta en TCP Vegas y FAST, su dinámica de flujo es muy similar matemáticamente. En el caso de FAST, ajusta el tamaño de ventana de forma brusca, (aumentándolo o disminuyéndolo), cuando el número de paquetes en el buffer es muy lejano a su objetivo, y por otro lado, lo ajusta de forma fina, cuando el número de paquetes en buffer y su objetivo no difiere mucho. En este sentido, FAST es una versión de alta velocidad de TCP Vegas.
El problema que tiene este protocolo es en el caso de redes en las que hay retrasos en los datos de “feedback”. En una red sin dichos retrasos se espera que el protocolo sea localmente estable. En el caso que haya retrasos, será localmente estable si hay poca variedad de retardos de flujo.
- Data control: este componente selecciona cuál será el siguiente paquete a enviar, y lo hace de entre tres grupos candidatos posibles:
- Los paquetes nuevos
- Paquetes que están definitivamente perdidos (se ha recibido un ACK negativo)
- Paquetes de los que no se ha recibido confirmación.
En caso de que no haya pérdida, los paquetes nuevos son enviados secuencialmente conforme los paquetes antiguos van siendo confirmados. A esto se le llama “self-clocking” o “ack-clocking”. En caso de pérdidas, se ha de decidir entre retransmitir paquetes, continuar enviando nuevos o retransmitir paquetes aun más antiguos que se han declarado como perdidos. El “data control” será el encargado de decidir cómo mezclar dichos paquetes a la hora de transmitirlos. Dicha decisión tomará aún más importancia conforme la relación ancho de banda – retardos aumente.
- Burstiness control: este componente rastrea las transmisiones de paquetes de manera fluida para averiguar cual es el ancho de banda disponible. Esto es especialmente importante en redes de un gran ancho de banda con presencia de retardo de paquetes, donde el tráfico puede ser a ráfagas debido a eventos tanto en la red como en los hosts. A veces una CPU transmisora está ocupada durante un largo periodo de tiempo atendiendo las interrupciones de los paquetes entrantes, permitiendo a los paquetes de salida acumularse en una cola de salida de manera que serán transmitidos en una gran ráfaga cuando la CPU quede libre. Una transmisión de este estilo crea grandes colas e incrementa la posibilidad de pérdidas masivas (burstiness).
El pacing (dividir en pasos) es una manera común de resolver el problema de burstiness en el transmisor. Una implementación simple de pacing permite al transmisor TCP planificar transmisiones de paquetes en intervalos de tiempo constantes, que se obtiene dividiendo la ventana de congestión entre el RTT. En la práctica esto requeriría una alta resolución en el reloj y provocaría sobrecarga. Para reducir la sobrecarga, podemos hacer una planificación en pequeñas ráfagas de paquetes en lugar de paquetes individuales. Sin embargo, la utilización del pacing no resuelve del todo el problema de burstiness.
Se emplean dos mecanismos de control de burstiness, uno para suplir el self-clocking y otro para incrementar sensiblemente el tamaño de la ventana en pequeñas ráfagas.
Limitaciones
Aquí se exponen algunos problemas de FAST TCP y sus soluciones potenciales, aunque se requiere de más experimentación para concluir la efectividad de las soluciones propuestas en redes reales y sus aplicaciones.
Medida del retardo de propagación
El retardo de propagación se usa en el algoritmo de control de ventana. En redes en las que existan flujos FAST, el retraso de cola, impuesto por el protocolo, puede ser confundido como parte del retraso de propagación de nuevos flujos que se incorporen después. Esta medida del retardo de propagación también puede verse afectada por un cambio de ruta desde un camino más corto hasta un camino más largo durante el tiempo de vida de una conexión, por ello una solución propuesta es estimar el retardo mediante el mínimo RTT observado durante un cierto periodo, no desde el inicio de la conexión, ya que la ruta puede cambiar.
Medida del retardo por espera en cola
Esta medida puede verse afectada por el burstiness de los mismos flujos FAST, llevando esta situación a disminuir la no imparcialidad entre los diferentes flujos con diferentes RTTs. Este error puede disminuirse notablemente desplegando un algoritmo de control de burstiness en el emisor.
α sintonizada
El parámetro α en la ecuación del window control controla el número de paquetes que cada flujo tiene en el enlace de cuello de botella, si este número supera la capacidad del buffer, los flujos no podrán alcanzar el equilibrio antes de que puedan observar la pérdida de paquetes y el algoritmo oscilará.
Protocolos heterogéneos
El problema de la maximización de aplicaciones implica que solo existe un único punto de equilibrio para redes bajo condiciones leves. Pero resulta que una red con protocolos heterogéneos que reaccionan a diferentes señales de congestión pueden comportarse de una manera mucho más compleja.
Conclusiones
A diferencia de TCP Reno y sus variantes, FAST TCP está basado en retrasos. Esto le permite alcanzar una alta utilización sin tener que llenar el buffer, lo que provocaría un retraso considerable de colas, como suele ocurrir en los algoritmos basados en pérdidas. Esto proporciona imparcialidad y no penaliza flujos con grandes RTTs.
Enlaces externos
- Página oficial FAST TCP (en inglés)
Categorías: Protocolos de Internet | Redes informáticas
Wikimedia foundation. 2010.