- Algoritmo de Huffman
-
El algoritmo de Huffman es un algoritmo para la construcción de códigos de Huffman, desarrollado por David A. Huffman en 1952 y descrito en A Method for the Construction of Minimum-Redundancy Codes.[1]
Este algoritmo toma un alfabeto de n símbolos, junto con sus frecuencias de aparición asociadas, y produce un código de Huffman para ese alfabeto y esas frecuencias.
Contenido
Descripción
El algoritmo consiste en la creación de un árbol binario que tiene cada uno de los símbolos por hoja, y construido de tal forma que siguiéndolo desde la raíz a cada una de sus hojas se obtiene el código Huffman asociado.
- Se crean varios árboles, uno por cada uno de los símbolos del alfabeto, consistiendo cada uno de los árboles en un nodo sin hijos, y etiquetado cada uno con su símbolo asociado y su frecuencia de aparición.
- Se toman los dos árboles de menor frecuencia, y se unen creando un nuevo árbol. La etiqueta de la raíz será la suma de las frecuencias de las raíces de los dos árboles que se unen, y cada uno de estos árboles será un hijo del nuevo árbol. También se etiquetan las dos ramas del nuevo árbol: con un 0 la de la izquierda, y con un 1 la de la derecha.
- Se repite el paso 2 hasta que sólo quede un árbol.
Con este árbol se puede conocer el código asociado a un símbolo, así como obtener el símbolo asociado a un determinado código.
Para obtener el código asociado a un símbolo se debe proceder del siguiente modo:
- Comenzar con un código vacío
- Iniciar el recorrido del árbol en la hoja asociada al símbolo
- Comenzar un recorrido del árbol hacia arriba
- Cada vez que se suba un nivel, añadir al código la etiqueta de la rama que se ha recorrido
- Tras llegar a la raíz, invertir el código
- El resultado es el código Huffman deseado
Para obtener un símbolo a partir de un código se debe hacer así:
- Comenzar el recorrido del árbol en la raíz de éste
- Extraer el primer símbolo del código a descodificar
- Descender por la rama etiquetada con ese símbolo
- Volver al paso 2 hasta que se llegue a una hoja, que será el símbolo asociado al código
En la práctica, casi siempre se utiliza el árbol para obtener todos los códigos de una sola vez; luego se guardan en tablas y se descarta el árbol.
Ejemplo de uso
La tabla describe el alfabeto a codificar, junto con las frecuencias de sus símbolos. En el gráfico se muestra el árbol construido a partir de este alfabeto siguiendo el algoritmo descrito.
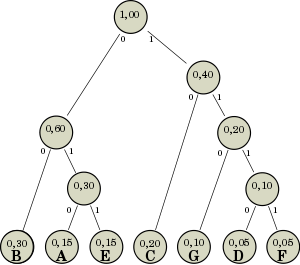 Árbol para construir el código Huffman del ejemplo.
Árbol para construir el código Huffman del ejemplo.
Símbolo Frecuencia A 0,15 B 0,30 C 0,20 D 0,05 E 0,15 F 0,05 G 0,10 Se puede ver con facilidad cuál es el código del símbolo E: subiendo por el árbol se recorren ramas etiquetadas con 1, 1 y 0; por lo tanto, el código es 011. Para obtener el código de D se recorren las ramas 0, 1, 1 y 1, por lo que el código es 1110.
La operación inversa también es fácil de realizar: dado el código 10 se recorren desde la raíz las ramas 1 y 0, obteniéndose el símbolo C. Para descodificar 010 se recorren las ramas 0, 1 y 0, obteniéndose el símbolo A.
Wikimedia foundation. 2010.
Algoritmo de Huffman — El Algoritmo de Huffman es un algoritmo para la construcción de códigos de Huffman, desarrollado por David A. Huffman en 1952 y descrito en A Method for the Construction of Minimum Redundancy Codes. Este algoritmo toma un alfabeto de n símbolos,… … Enciclopedia Universal
Huffman — El término Huffman puede referirse a: la codificación Huffman, una codificación utilizada para compresión de datos; el algoritmo de Huffman, un algoritmo para la construcción de códigos de Huffman; David Albert Huffman, personaje ilustre en el… … Wikipedia Español
Algoritmo de compresión sin pérdida — Se denomina algoritmo de compresión sin pérdida a cualquier procedimiento de codificación que tenga como objetivo representar cierta cantidad de información utilizando u ocupando una fracción menor en unidad de almacenamiento de datos establecida … Wikipedia Español
Codificación Huffman — Árbol de Huffman generado para las frecuencias de apariciones exactas del texto Esto es un ejemplo de árbol de Huffman . las frecuencias y códigos de cada carácter se muestran abajo. Codificar esta frase usando este código requiere 156 bits, sin… … Wikipedia Español
Código canónico de Huffman — Un código canónico de Huffman es un tipo particular de codificación Huffman que tiene la propiedad de poder ser descrito de una forma muy compacta. Los compresores de datos generalmente trabajan de una de dos formas posibles. O bien el… … Wikipedia Español
David A. Huffman — Saltar a navegación, búsqueda David A. Huffman Nacimiento 9 de agosto de 1925 … Wikipedia Español
Deflación (algoritmo) — Para otros usos de este término, véase deflación. El algoritmo deflación, en inglés denominado DEFLATE, es un algoritmo de compresión de datos sin pérdidas que usa una combinación del algoritmo LZ77 y la codificación Huffman. Fue originalmente… … Wikipedia Español
Prediction by Partial Matching (Algoritmo de compresión) — Saltar a navegación, búsqueda El algoritmo Prediction by Partial Matching (en español Predicción por Coincidencia Parcial) o PPM es una técnica adaptativa estadística de compresión de datos basada en el modelo de contexto y predicción. Los… … Wikipedia Español
Deflación (algoritmo) — El algoritmo deflación es un sistema de compresión de datos sin perdidas que usa una combinación del algoritmo LZ77 y la codificación Huffman. Fue originalmente definido por Phil Katz para la versión 2 de su herramienta de archivado PKZIP, y fue… … Enciclopedia Universal
LD-AAC — Low Delay Advanced Audio Coding (LD AAC o AAC LD) significa, en inglés, codificación de audio avanzada con retardo bajo. Es el estándar de codificación de audio, dentro de MPEG 4, que ofrece una mejor relación entre calidad de audio y retardo de… … Wikipedia Español
Algoritmo de Huffman

18+
© Academic, 2000-2026
- Contacte con nosotros: Apoyo técnico, Publicidad
Exportación Diccionarios, creado en PHP, Joomla, Drupal, WordPress, MODx.