- Algoritmo de Kruskal
-
El algoritmo de Kruskal es un algoritmo de la teoría de grafos para encontrar un árbol recubridor mínimo en un grafo conexo y ponderado. Es decir, busca un subconjunto de aristas que, formando un árbol, incluyen todos los vértices y donde el valor total de todas las aristas del árbol es el mínimo. Si el grafo no es conexo, entonces busca un bosque expandido mínimo (un árbol expandido mínimo para cada componente conexa). El algoritmo de Kruskal es un ejemplo de algoritmo voraz.
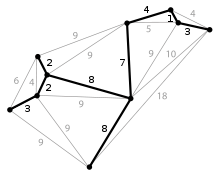 Un ejemplo de árbol expandido mínimo. Cada punto representa un vértice, el cual puede ser un árbol por sí mismo. Se usa el Algoritmo para buscar las distancias más cortas (árbol expandido) que conectan todos los puntos o vértices.
Un ejemplo de árbol expandido mínimo. Cada punto representa un vértice, el cual puede ser un árbol por sí mismo. Se usa el Algoritmo para buscar las distancias más cortas (árbol expandido) que conectan todos los puntos o vértices.
Funciona de la siguiente manera:
- se crea un bosque B (un conjunto de árboles), donde cada vértice del grafo es un árbol separado
- se crea un conjunto C que contenga a todas las aristas del grafo
- mientras C es no vacío
- eliminar una arista de peso mínimo de C
- si esa arista conecta dos árboles diferentes se añade al bosque, combinando los dos árboles en un solo árbol
- en caso contrario, se desecha la arista
Al acabar el algoritmo, el bosque tiene un solo componente, el cual forma un árbol de expansión mínimo del grafo.
Este algoritmo fue publicado por primera vez en Proceedings of the American Mathematical Society, pp. 48–50 en 1956, y fue escrito por Joseph Kruskal.
Contenido
Pseudocódigo
1 function Kruskal(G) 2 for each vertex v in G do 3 Define an elementary cluster C(v) ← {v}. 4 Initialize a priority queue Q to contain all edges in G, using the weights as keys. 5 Define a tree T ← Ø //T will ultimately contain the edges of the MST 6 // n es el número total de vértices 7 while T has fewer than n-1 edges do 8 // edge u, v is the minimum weighted route from/to v 9 (u,v) ← Q.removeMin() 10 // previene ciclos en T. suma u, v solo si T no contiene una arista que una u y v. 11 // Nótese que el cluster contiene más de un vértice si una arista une un par de 12 // vértices que han sido añadidos al árbol. 13 Let C(v) be the cluster containing v, and let C(u) be the cluster containing u. 14 if C(v) ≠ C(u) then 15 Add edge (v,u) to T. 16 Merge C(v) and C(u) into one cluster, that is, union C(v) and C(u). 17 return tree TCódigo en C++
// Declaraciones en el archivo .h int cn; //cantidad de nodos vector< vector<int> > ady; //matriz de adyacencia // Devuelve la matriz de adyacencia del arbol minimo. vector< vector<int> > Grafo :: kruskal(){ vector< vector<int> > adyacencia = this->ady; vector< vector<int> > arbol(cn); vector<int> pertenece(cn); // indica a que arbol pertenece el nodo for(int i = 0; i < cn; i++){ arbol[i] = vector<int> (cn, INF); pertenece[i] = i; } int nodoA; int nodoB; int arcos = 1; while(arcos < cn){ // Encontrar el arco minimo que no forma ciclo y guardar los nodos y la distancia. int min = INF; for(int i = 0; i < cn; i++) for(int j = 0; j < cn; j++) if(min > adyacencia[i][j] && pertenece[i] != pertenece[j]){ min = adyacencia[i][j]; nodoA = i; nodoB = j; } // Si los nodos no pertenecen al mismo arbol agrego el arco al arbol minimo. if(pertenece[nodoA] != pertenece[nodoB]){ arbol[nodoA][nodoB] = min; arbol[nodoB][nodoA] = min; // Todos los nodos del arbol del nodoB ahora pertenecen al arbol del nodoA. int temp = pertenece[nodoB]; pertenece[nodoB] = pertenece[nodoA]; for(int k = 0; k < cn; k++) if(pertenece[k] == temp) pertenece[k] = pertenece[nodoA]; arcos++; } } return arbol; }
Complejidad del algoritmo
m el número de aristas del grafo y n el número de vértices, el algoritmo de Kruskal muestra una complejidad O(m log m) o, equivalentemente, O(m log n), cuando se ejecuta sobre estructuras de datos simples. Los tiempos de ejecución son equivalentes porque:
- m es a lo sumo n2 y log n2 = 2logn es O(log n).
- ignorando los vértices aislados, los cuales forman su propia componente del árbol de expansión mínimo, n ≤ 2m, así que log n es O(log m).
Se puede conseguir esta complejidad de la siguiente manera: primero se ordenan las aristas por su peso usando una ordenación por comparación (comparison sort) con una complejidad del orden de O(m log m); esto permite que el paso "eliminar una arista de peso mínimo de C" se ejecute en tiempo constante. Lo siguiente es usar una estructura de datos sobre conjuntos disjuntos (disjoint-set data structure) para controlar qué vértices están en qué componentes. Es necesario hacer orden de O(m) operaciones ya que por cada arista hay dos operaciones de búsqueda y posiblemente una unión de conjuntos. Incluso una estructura de datos sobre conjuntos disjuntos simple con uniones por rangos puede ejecutar las operaciones mencionadas en O(m log n). Por tanto, la complejidad total es del orden de O(m log m) = O(m log n).
Con la condición de que las aristas estén ordenadas o puedan ser ordenadas en un tiempo lineal (por ejemplo, mediante el ordenamiento por cuentas o con el ordenamiento Radix), el algoritmo puede usar estructuras de datos de conjuntos disjuntos más complejas para ejecutarse en tiempos del orden de O(m α(n)), donde α es la inversa (tiene un crecimiento extremadamente lento) de la función de Ackermann.
Demostración de la corrección
Sea P un grafo conexo y valuado y sea Y el subgrafo de P producido por el algoritmo. Y no puede tener ciclos porque cada vez que se añade una arista, ésta debe conectar vértices de dos árboles diferentes y no vértices dentro de un subárbol. Y no puede ser disconexa ya que la primera arista que une dos componentes de Y debería haber sido añadida por el algoritmo. Por tanto, Y es un árbol expandido de P.
Sea Y1 el árbol expandido de peso mínimo de P, el cual tiene el mayor número de aristas en común con Y. Si Y1=Y entonces Y es un árbol de expansión mínimo. Por otro lado, sea e la primera arista considerada por el algoritmo que está en Y y que no está en Y1. Sean C1 y C2 las componentes de P que conecta la arista e. Ya que Y1 es un árbol, Y1+e tiene un ciclo y existe una arista diferente f en ese ciclo que también conecta C1 y C2. Entonces Y2=Y1+e-f es también un árbol expandido. Ya que e fue considerada por el algoritmo antes que f, el peso de e es al menos igual que que el peso de f y ya que Y1 es un árbol expandido mínimo, los pesos de esas dos aristas deben ser de hecho iguales. Por tanto, Y2 es un árbol expandido mínimo con más aristas en común con Y que las que tiene Y1, contradiciendo las hipótesis que se habían establecido antes para Y1. Esto prueba que Y debe ser un árbol expandido de peso mínimo.
Otros algoritmos para este problema son el algoritmo de Prim y el algoritmo de Boruvka.
Ejemplo
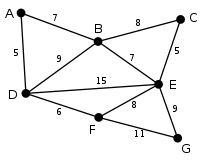
Este es el grafo original. Los números de las aristas indican su peso. Ninguna de las aristas está resaltada. 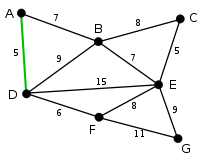
AD y CE son las aristas más cortas, con peso 5, y AD se ha elegido arbitrariamente, por tanto se resalta. 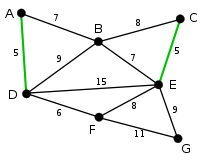
Sin embargo, ahora es CE la arista más pequeña que no forma ciclos, con peso 5, por lo que se resalta como segunda arista. 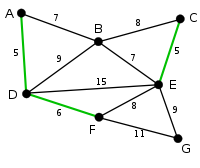
La siguiente arista, DF con peso 6, ha sido resaltada utilizando el mismo método. 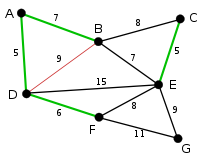
La siguientes aristas más pequeñas son AB y BE, ambas con peso 7. AB se elige arbitrariamente, y se resalta. La arista BD se resalta en rojo, porque formaría un ciclo ABD si se hubiera elegido. 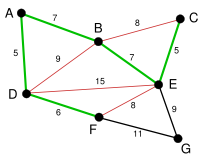
El proceso continúa marcando las aristas, BE con peso 7. Muchas otras aristas se marcan en rojo en este paso: BC (formaría el ciclo BCE), DE (formaría el ciclo DEBA), y FE (formaría el ciclo FEBAD). 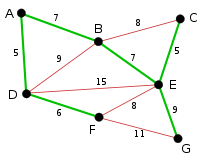
Finalmente, el proceso termina con la arista EG de peso 9, y se ha encontrado el árbol expandido mínimo. Referencias
- J. B. Kruskal: On the shortest spanning subtree and the traveling salesman problem. En: Proceedings of the American Mathematical Society. 7 (1956), pp. 48–50
- Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest y Clifford Stein. Introduction to Algorithms, Second Edition. MIT Press and McGraw-Hill, 2001. ISBN 0-262-03293-7. Sección 23.2: The algorithms of Kruskal and Prim, pp.567–574.
Enlaces externos
Categorías:- Algoritmos de grafos
- Árboles (estructura)








Wikimedia foundation. 2010.