- Weka (aprendizaje automático)
-

Weka 
Desarrollador Universidad de Waikato (Nueva Zelanda)
www.cs.waikato.ac.nz/~ml/weka/Información general Última versión estable 3.4.18 (book), 3.6.4 (stable), 3.7.3 (development)
9 de Diciembre de 2010Género Aprendizaje automático Sistema operativo Multiplataforma Licencia GPL En español 
Weka (Waikato Environment for Knowledge Analysis - Entorno para Análisis del Conocimiento de la Universidad de Waikato) es una plataforma de software para aprendizaje automático y minería de datos escrito en Java y desarrollado en la Universidad de Waikato. Weka es un software libre distribuido bajo licencia GNU-GPL.
Contenido
Breve historia
- En 1993, la Universidad de Waikato de Nueva Zelanda inició el desarrollo de la versión original de Weka (en TCL/TK y C).
- En 1997, se decidió reescibir el código en Java incluyendo implementaciones de algoritmos de modelado.[1]
- En 2005, Weka recibe de SIGKDD[2] [3] (Special Interest Group on Knowledge Discovery and Data Mining) el galardón "Data Mining and Knowledge Discovery Service".
- Puesto en el ranking de Sourceforge.net el 19 de mayo de 2008: 248 (con 1,186,740 descargas).
Descripción
El paquete Weka[4] contiene una colección de herramientas de visualización y algoritmos para análisis de datos y modelado predictivo, unidos a una interfaz gráfica de usuario para acceder fácilmente a sus funcionalidades. La versión original de Weka fue un front-end en TCL/TK para modelar algoritmos implementados en otros lenguajes de programación, más unas utilidades para preprocesamiento de datos desarrolladas en C para hacer experimentos de aprendizaje automático. Esta versión original se diseñó inicialmente como herramienta para analizar datos procedentes del dominio de la agricultura,[5] [6] pero la versión más reciente basada en Java (WEKA 3), que empezó a desarrollarse en 1997, se utiliza en muchas y muy diferentes áreas, en particular con finalidades docentes y de investigación.
Razones a favor de Weka
Los puntos fuertes de Weka son:
- Está disponible libremente bajo la licencia pública general de GNU.
- Es muy portable porque está completamente implementado en Java y puede correr en casi cualquier plataforma.
- Contiene una extensa colección de técnicas para preprocesamiento de datos y modelado.
- Es fácil de utilizar por un principiante gracias a su interfaz gráfica de usuario.
Weka soporta varias tareas estándar de minería de datos, especialmente, preprocesamiento de datos, clustering, clasificación, regresión, visualización, y selección. Todas las técnicas de Weka se fundamentan en la asunción de que los datos están disponibles en un fichero plano (flat file) o una relación, en la que cada registro de datos está descrito por un número fijo de atributos (normalmente numéricos o nominales, aunque también se soportan otros tipos). Weka también proporciona acceso a bases de datos vía SQL gracias a la conexión JDBC (Java Database Connectivity) y puede procesar el resultado devuelto por una consulta hecha a la base de datos. No puede realizar minería de datos multi-relacional, pero existen aplicaciones que pueden convertir una colección de tablas relacionadas de una base de datos en una única tabla que ya puede ser procesada con Weka.[7]
Carencias de Weka
Un área importante que actualmente no cubren los algoritmos incluidos en Weka es el modelado de secuencias.
La interfaz de usuario

Al ejecutar la aplicación nos aparece el selector de interfaz de Weka (Weka GUI Chooser) que da la opción de seleccionar entre cuatro posibles interfaces de usuario para acceder a las funcionalidades del programa, éstas son "Simple CLI", "Explorer", "Experimenter" y "Knowledge Flow".
Simple CLI
Simple CLI es la abreviatura de Simple Command-Line Interface (Interfaz Simple de Línea de Comandos); se trata de una consola que permite acceder a todas las opciones de Weka desde línea de comandos.
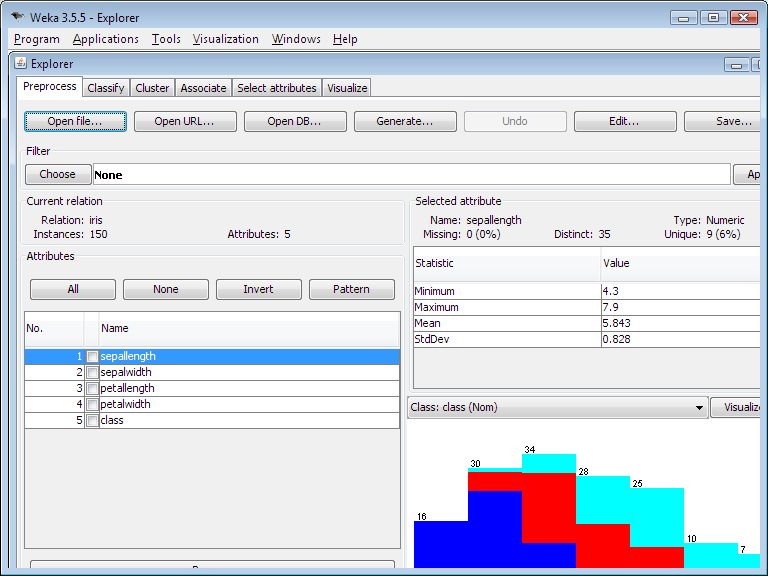
Explorer
La interfaz Explorer (Explorador) dispone de varios paneles que dan acceso a los componentes principales del banco de trabajo:
-
- El panel "Preprocess" dispone de opciones para importar datos de una base de datos, de un fichero CSV, etc., y para preprocesar estos datos utilizando los denominados algoritmos de filtrado. Estos filtros se pueden utilizar para transformar los datos (por ejemplo convirtiendo datos numéricos en valores discretos) y para eliminar registros o atributos según ciertos criterios previamente especificados.
-
- El panel "Classify" permite al usuario aplicar algoritmos de clasificación estadística y análisis de regresión (denominados todos clasificadores en Weka) a los conjuntos de datos resultantes, para estimar la exactitud del modelo predictivo resultante, y para visualizar predicciones erróneas, curvas ROC, etc., o el propio modelo (si este es susceptible de ser visualizado, como por ejemplo un árbol de decisión).
-
- El panel "Associate" proporciona acceso a las reglas de asociación aprendidas que intentan identificar todas las interrelaciones importantes entre los atributos de los datos
-
Categorías:
- Aprendizaje automático
- Minería de datos
- Software libre
- Inteligencia artificial
- Software programado en Java
- Paquetes de software estadístico
Wikimedia foundation. 2010.
Aprendizaje automático — Este artículo o sección necesita referencias que aparezcan en una publicación acreditada, como revistas especializadas, monografías, prensa diaria o páginas de Internet fidedignas. Puedes añadirlas así o avisar … Wikipedia Español
Weka (desambiguación) — El término Weka puede hacer referencia a lo siguiente: El weka (o Gallirallus australis), es un ave de Nueva Zelanda. Weka, es un paquete de software para aprendizaje automático escrito en la Universidad de Waikato … Wikipedia Español
Clasificadores (matemático) — Este artículo o sección necesita referencias que aparezcan en una publicación acreditada, como revistas especializadas, monografías, prensa diaria o páginas de Internet fidedignas. Puedes añadirlas así o avisar … Wikipedia Español
Minería de datos — La minería de datos (DM, Data Mining) consiste en la extracción no trivial de información que reside de manera implícita en los datos. Dicha información era previamente desconocida y podrá resultar útil para algún proceso. En otras palabras, la… … Wikipedia Español
Algoritmo apriori — El algoritmo apriori se usa en minería de datos para encontrar Reglas de asociación en un conjunto de datos. Este algoritmo se basa en el conocimiento previo o “a priori” de los conjuntos frecuentes, esto sirve para reducir el espacio de búsqueda … Wikipedia Español
General Architecture for Text Engineering — GATE ventana principal de GATE Developer v5 Desarrollador GATE research team … Wikipedia Español
Reglas de asociación — Saltar a navegación, búsqueda En minería de datos y aprendizaje automático, las reglas de asociación se utilizan para descubrir hechos que ocurren en común dentro de un determinado conjunto de datos.[1] Se han investigado ampliamente diversos… … Wikipedia Español
KNIME — Desarrollador KNIME.com GmbH knime.org Información general Última versión en pruebas 2.3.3 16 de marzo de 2011 … Wikipedia Español
RapidMiner — Saltar a navegación, búsqueda RapidMiner Desarrollador Rapid I http://rapidminer.com Información general S.O … Wikipedia Español
Weka (aprendizaje automático)
18+
© Academic, 2000-2026
- Contacte con nosotros: Apoyo técnico, Publicidad
Exportación Diccionarios, creado en PHP, Joomla, Drupal, WordPress, MODx.