- Reglas de asociación
-
Reglas de asociación
En minería de datos y aprendizaje automático, las reglas de asociación se utilizan para descubrir hechos que ocurren en común dentro de un determinado conjunto de datos.[1] Se han investigado ampliamente diversos métodos para aprendizaje de reglas de asociación que han resultado ser muy interesantes para descubrir relaciones entre variables en grandes conjuntos de datos.
Piatetsky-Shapiro[2] describe el análisis y la presentación de reglas 'fuertes' descubiertas en bases de datos utilizando diferentes medidas de interés. Basado en el concepto de regla fuerte, Agrawal et al.[3] presentaron un trabajo en el que indicaban las reglas de asociación que descubrían las relaciones entre los datos recopilados a gran escala en los sistemas de terminales de punto de venta de unos supermercados. Por ejemplo, la siguiente regla:
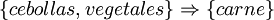
Encontrada en los datos de ventas de un supermercado, indicaría que un consumidor que compra cebollas y vegetales a la vez, es probable que compre también carne. Esta información se puede utilizar como base para tomar decisiones sobre marketing como precios promocionales para ciertos productos o donde ubicar éstos dentro del supermercado. Además del ejemplo anterior aplicado al análisis de la cesta de la compra, hoy en día, las reglas de asociación también son de aplicación en otras muchas áreas como el Web mining, la detección de intrusos o la bioinformática.
Contenido
El ejemplo más popular
Un caso muy famoso sobre reglas de asociación es el de la "cerveza y los pañales", basado en el comportamiento de los compradores en el supermercado. Se descubrió que muchos hombres acaban comprando pañales por encargo de sus esposas. En la cadena de supermercados Wal-Mart, donde se descubrió este hecho, se adoptó la medida de colocar la cerveza junto a los pañales. De esta manera consiguió aumentar la venta de cerveza.
Definición del problema
Según la definición original de Agrawal et al[3] el problema de minería de reglas de asociación se define como:
- Sea
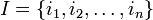 un conjunto de n atributos binarios llamados items.
un conjunto de n atributos binarios llamados items.
- Sea
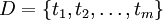 un conjunto de transacciones almacenadas en una base de datos.
un conjunto de transacciones almacenadas en una base de datos.
Cada transacción en
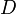 tiene un ID (identificador) único y contiene un subconjunto de items de
tiene un ID (identificador) único y contiene un subconjunto de items de 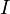 . Una regla se define como una implicación de la forma:
. Una regla se define como una implicación de la forma:Donde:
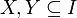 y
y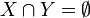
Los conjuntos de items
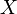 y
y 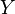 se denominan respectivamente "antecedente" (o parte izquierda) y "consecuente" (o parte derecha) de la regla.
se denominan respectivamente "antecedente" (o parte izquierda) y "consecuente" (o parte derecha) de la regla.Ejemplo práctico
Ejemplo:
Base de datos con 4 items y 5 transaccionesID Leche Pan Mantequilla Cerveza 1 1 1 0 0 2 0 1 1 0 3 0 0 0 1 4 1 1 1 0 5 0 1 0 0 Para ilustrar estos conceptos véase el siguiente ejemplo sobre ventas en un supermercado. El conjunto de items es:
A la derecha se muestra una pequeña base de datos que contiene los items, donde el código '1' se interpreta como que el producto (item) correspondiente está presenta en la transacción y el código '0' significa que dicho producto no esta presente. Un ejemplo de regla para el supermercado podría ser:
Significaría que si el cliente compró 'leche' y 'pan' también compró 'mantequilla', es decir, según la especificación formal anterior se tendría que:
Reglas significativas, 'soporte' y 'confianza'
Nótese que el ejemplo anterior es muy pequeño, en la práctica, una regla necesita un soporte de varios cientos de registros (transacciones) antes de que ésta pueda considerarse significativa desde un punto de vista estadístico. A menudo las bases de datos contienen miles o incluso millones de registros.
Para seleccionar reglas interesantes del conjunto de todas las reglas posibles que se pueden derivar de un conjunto de datos se pueden utilizar restricciones sobre diversas medidas de "significancia" e "interés". Las restricciones más conocidas son los umbrales mínimos de "soporte" y "confianza".
El 'soporte' de un conjunto de items
en una base de datos se define como la proporción de transacciones en la base de datos que contiene dicho conjunto de items:En el ejemplo anterior el conjunto
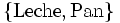 tiene un soporte de;
tiene un soporte de;Es decir, el soporte es del 40% (2 de cada 5 transacciones).
La 'confianza' de una regla se define como:
Por ejemplo, para la regla:
La confianza sería:
Este cálculo significa que el 50% de las reglas de la base de datos que contienen 'leche' y 'pan' en el antecedente la también tienen 'mantequilla' en el consecuente; en otras palabras, que la regla:
Es cierta en el 50% de los casos.
La confianza puede interpretarse como un estimador de P(Y | X), la probabilidad de encontrar la parte derecha de una regla condicionada a que se encuentre también la parte izquierda[4] .
Las reglas de asociación deben satisfacer las especificaciones del usuario en cuanto a umbrales mínimos de soporte y confianza. Para conseguir esto el proceso de generación de reglas de asociación se realiza en dos pasos. Primero se aplica el soporte mínimo para encontrara los conjuntos de items más frecuentes en la base de datos. En segundo lugar se forman las reglas partiendo de estos conjuntos frecuentes de items y de la restricción de confianza mínima.
Encontrar todos los subconjuntos frecuentes de la base de datos es difícil ya que esto implica considerar todos los posibles subconjuntos de items (combinaciones de items). El conjunto de posibles conjuntos de items es el conjunto potencia de I y su tamaño es de 2n − 1 (excluyendo el conjunto vacío que no es válido como conjunto de items). Aunque el tamaño del conjunto potencia crece exponencialmente con el número de items n de I, es posible hacer una búsqueda eficiente utilizando la propiedad "downward-closure" del soporte[3] (también llamada anti-monótona[5] ) que garantiza que para un conjunto de items frecuente, todos sus subconjuntos también son frecuentes, y del mismo modo, para un conjunto de items infrecuente, todos sus superconjuntos deben ser infrecuentes. Explotando esta propiedad se han diseñado algoritmos eficientes (por ejemplo: Apriori[6] y Eclat[7] ) para encontrar los items frecuentes.
El 'lift', indica cual es la proporcion entre el soporte observado de un conjunto de productos respecto del soporte teorico de ese conjunto dado el supuesto de independencia. Un valor de lift = 1 indica que ese conjunto aparece una cantidad de veces acorde a lo esperado bajo condiciones de independencia. Un valor de lift > 1 indica que ese conjunto aparece una cantidad de veces superior a lo esperado bajo condiciones de independencia (por lo que se puede intuir que existe una relación que hace que los productos se encuentren en el conjunto mas veces de lo normal). Un valor de lift < 1 indica que ese conjunto aparece una cantidad de veces inferior a lo esperado bajo condiciones de independencia (por lo que se puede intuir que existe una relacion que hace que los productos no esten formando parte del mismo conjunto mas veces de lo normal)
Algoritmos
Existen diversos algoritmos que realizan búsquedas de reglas de asociación bases de datos.
- Apriori
- Partition
- Eclat
Referencias
- ↑ T. Menzies, Y. Hu. Data Mining For Busy People. IEEE Computer, Outubro de 2003, pgs. 18-25.
- ↑ Piatetsky-Shapiro, G. (1991), Discovery, analysis, and presentation of strong rules, in G. Piatetsky-Shapiro & W. J. Frawley, eds, ‘Knowledge Discovery in Databases’, AAAI/MIT Press, Cambridge, MA.
- ↑ a b c R. Agrawal; T. Imielinski; A. Swami: Mining Association Rules Between Sets of Items in Large Databases", SIGMOD Conference 1993: 207-216
- ↑ Jochen Hipp, Ulrich Güntzer, and Gholamreza Nakhaeizadeh. Algorithms for association rule mining - A general survey and comparison. SIGKDD Explorations, 2(2):1-58, 2000.
- ↑ Jian Pei, Jiawei Han, and Laks V.S. Lakshmanan. Mining frequent itemsets with convertible constraints. In Proceedings of the 17th International Conference on Data Engineering, April 2-6, 2001, Heidelberg, Germany, pages 433-442, 2001.
- ↑ Rakesh Agrawal and Ramakrishnan Srikant. Fast algorithms for mining association rules in large databases. In Jorge B. Bocca, Matthias Jarke, and Carlo Zaniolo, editors, Proceedings of the 20th International Conference on Very Large Data Bases, VLDB, pages 487-499, Santiago, Chile, September 1994.
- ↑ Mohammed J. Zaki. Scalable algorithms for association mining. IEEE Transactions on Knowledge and Data Engineering, 12(3):372-390, May/June 2000.
Véase también
Enlaces externos
Bibliografía
- Annotated Bibliography on Association Rules by M. Hahsler
Implementaciones
- arules, paquete para minerís de reglas de asociación con R.
- Implementaciones en C de los algoritmos Apriori y Eclat
- FIMI (Frequent Itemset Mining Implementations Repository)
- Frequent pattern mining implementations from Bart Goethals
- Weka, colección de algoritmos para taréas de minería de datos implementados en Java.
- Software de minería de datos deMohammed J. Zaki
Categorías: Minería de datos | Bancos de datos - Sea
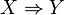
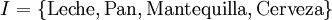
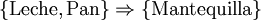
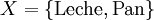
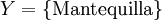
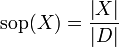
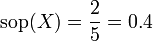
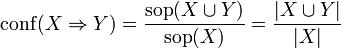
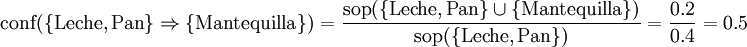
Wikimedia foundation. 2010.