- Metodologia de conocimiento
-
La metodología de conocimiento identifica tres tipos de información para que lo utilice el sistema de recomendación:
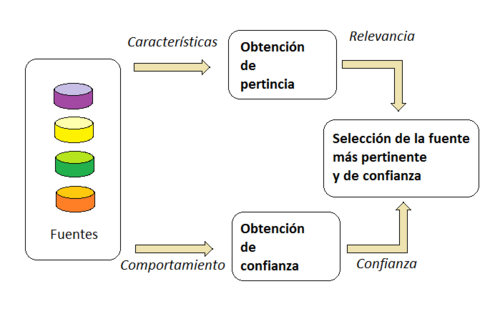 Esquema general de la metodología de conocimiento
Esquema general de la metodología de conocimiento
- 1. Información demográfica de los usuarios: edad, género, lugar de residencia ...
- 2. Preferencias de los usuarios de las características del producto: tipo de película, director, actor principal ...
- 3. Experiencias previas: evaluaciones de productos de compra ...
Sobre la base de datos de esta información, la afinidad que el usuario tiene se calcula para algunos productos y los productos con mayor afinidad se recomiendan para el usuario. Las fuentes que proporcionan información oportuna, exacta y pertinente se espera que sean utilizados con más frecuencia que las fuentes que proporcionan información irrelevante.
Contenido
Motivación
Uno de los retos más importantes tanto en un sistema de comercialización como en un sistema de recomendación es obtener información útil sobre el cliente o usuario de un determinado producto o servicio. En general, el primer paso es buscar información analizando cualquier fuente disponible. Sin embargo, el principal problema que surge es la utilidad de esta información. Por lo tanto, a priori, es necesario un mecanismo que proporcione pruebas sobre la pertinencia de esta información para las recomendaciones. Para evitar hacer una búsqueda sin fin en la enorme pila de datos disponibles, ya que se utilizan demasiados recursos, la información debe ser previamente clasificada o indexada por ser fácilmente encontrada. Esta metodología se ha definido específicamente para las fuentes de información estructurada.
Pasos que lo compone
- Obtención de un conjunto de características representativas de la información conte-nida en las fuentes: estas características deben permitir que la fuente más relevante sea comparada con las otras antes de ser elegida.
- Obtención de una medida para seleccionar la fuente más fiable: la confianza de una fuente se obtiene de los resultados de las recomendaciones formuladas anteriormente con esta fuente.
- Selección de la fuente más adecuada: para cada una de las fuentes disponibles se obtiene una medida de adecuación utilizando el valor de pertenencia obtenido en el paso 1 y el valor de confianza obtenido en el apartado 2. Esto sirve para decidir, de manera justificada, qué fuentes son las más adecuadas para las recomendaciones.
Obtención de pertinencia o relevancia (R(S))
Para saber cómo de pertinente es una fuente debemos mirar ciertas características:
- INTEGRIDAD: el objetivo es obtener información sobre los usuarios de las fuentes disponibles relacionadas con ellos. La base de datos que contiene información sobre todos los usuarios será más completa que la que sólo contiene información sobre algunos de los usuarios.
Dado un conjunto U de usuarios de un dominio de recomendación, la integridad (I) de una fuente S es la cantidad de usuarios de U sin S, conocido como | C | , dividido entre la cantidad de usuarios | U | .
- DIVERSIDAD: permite que se conozca la información demográfica contenida en las fuentes. Los sistemas de recomendación usan esta información para poder recomen-dar a grupos enteros según género, lugar donde viven, edad ... Cuanto más diversa sea la fuente, más grupos de usuarios deberán.
La diversidad (D) se calcula como la entropía, donde cada
 y, donde ni son los usuarios de un grupo I y N el número total de usuarios de la fuente S.
y, donde ni son los usuarios de un grupo I y N el número total de usuarios de la fuente S.- FRECUENCIA: ayuda a saber la cantidad de información que contiene la fuente. Una fuente obtiene la información a través de las interacciones con los usuarios, por lo tanto, según la frecuencia en que una fuente interactúa con los usuarios más completa será. Además, cuanta más información hay sobre un comportamiento, la compra o las evaluaciones de los usuarios, más precisas serán las recomendaciones.
Las fuente se dividen en categorías según el número de iteraciones:
- Categoría f1: 1-10 interacciones
- Categoría f2: 11-25 interacciones
- Categoría f3: 26-50 interacciones
- Categoría f4: 51-100 interacciones
- Categoría f5: 101-200 interacciones
- Categoría f6: +201 interacciones
La frecuencia (F) de las interacciones de una fuente S es la suma de pesos wy, dadas se categorías fy < / math > ,multiplicadopor < math > | fy | y dividido por el número de usuarios N de la fuente S.
- PUNTUALIDAD: las fuentes de disponer de información actualizada, ya que los gustos y preferencias de los usuarios pueden cambiar con el tiempo. Las películas que gustaban hace diez años pueden no ser las mismas que gustan ahora, pero hay más probabilidad de que se asemejen a las películas que más gustaban hace 2 años.
También hay categorías que se recogen los usuarios que han interaccionado con la fuente según periodos de tiempo:
- Categoría p1: 01/01/2006 - 31/12/2006
- Categoría p2: 01/01/2007 - 31/12/2007
- Categoría p3: 01/01/2008 - 31/12/2008
- Categoría p4: 01/01/2009 - 31/12/2009
- Categoría p5: 01/01/2010 - 31/12/2010
- Categoría p6: 01/01/2011 - 31/12/2011
La puntualidad (P) de las interacciones de una fuente S es la suma de pesos wi, dadas se categorías pi, multiplicado por | pi | y dividido por el número de usuarios N de la fuente S.
Finalmente conseguimos una medida de relevancia:
- NÚMERO DE ATRIBUTOS RELEVANTES: aunque la fuente sea completa, tenga una gran cantidad de información sobre los usuarios y esté actualizada, quizás no contiene la información exacta para hacer las recomendaciones. La cantidad de atributos relevantes es una característica que expresa si la información que buscamos se encuentra en una fuente o no.
Dado un conjunto D de atributos que permiten hacer la recomendación, el número de atributos relevantes (R) de una fuente S es la cantidad de atributos D sin S, llamado | B | , dividido entre la cantidad de atributos | D | .
Obtención de confianza (T(S))
La confianza de una fuente se define como la probabilidad de que una fuente sea evaluada por utilizar su información, es un valor entre 0 y 1. Este valor es la confianza ob-tenida a partir de observaciones del comportamiento pasado de las fuentes. La información necesaria para calcular el grado de éxito de las recomendaciones se guarda y se utiliza para evaluar las recomendaciones hechas con información de una fuente como exitosa (= 1) o no exitosa (= 0).
Selección de la fuente más pertinente y de confianza
El algoritmo se compone de tres elementos:
-
- 1.Un conjunto (S) de las fuentes candidatas.
-
- 2.Una función de selección (R (s), T (s)) para obtener las fuentes más relevantes (relevant en inglés) y fiables (trust en inglés). :: Esta función utiliza los valores de perte-nencia T y confianza R de las fuentes como parámetros.
-
- 3.Una un conjunto solución (F) que contiene las fuentes elegidas.
SELECCION(R(s),T(s)) = R(s) • T(s)
Referencias
- [1] (en inglés)
Wikiproyecto:Telecomunicaciones audiovisualesCategorías:- Telecomunicaciones
- Informática





Wikimedia foundation. 2010.