- Block matching
-
Block matching
Algoritmo utilizado en la estimación de movimiento, consistente en la eliminación de redundancia temporal entre dos o más fotogramas sucesivos. Se ha convertido en una técnica fundamental en la mayoría de los estándares de compresión y codificación de video basados en la compensación de movimiento.
Cada una de las imágenes pertenecientes a una secuencia de video se divide en bloques rectangulares (generalmente cuadrados) denominados macrobloques. El método pretende detectar el movimiento entre imágenes con respecto a los macrobloques que las constituyen.
Los bloques del fotograma actual son cotejados con los bloques del fotograma de destino o de referencia (anterior al actual, generalmente el primero), deslizando el actual a lo largo de una región concreta de píxeles del fotograma de destino.
Un criterio de semejanza determina la elección del bloque con mayor similitud (o que minimiza un error medido) de entre los candidatos dentro de la ventana de búsqueda de tamaño fijo del fotograma de referencia. Si el bloque elegido no se encuentra en la misma posición en ambas frames, significa que se ha movido. La distancia del bloque coincidente entre el fotograma actual y el de referencia se define como el vector de desplazamiento estimado, y será el que se le asigne a todos los píxeles del macrobloque.
En el caso ideal, los píxeles correspondientes de los bloques coincidentes serían exactamente iguales. No obstante, ese caso sucede en muy raras ocasiones, ya que la forma de los objetos en movimiento varía con respecto al punto de vista del observador o la luz reflejada sobre su superficie, y siempre nos veremos afectados por el ruido.
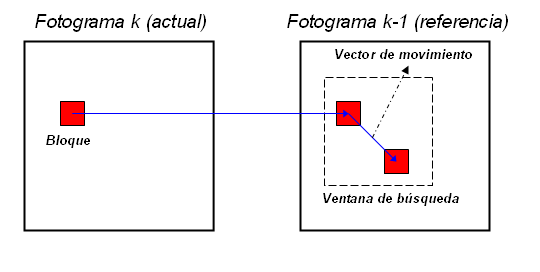 Algoritmo de Block matching
Algoritmo de Block matchingBloques que presentan un mismo patrón de desplazamiento pueden combinarse formando objetos en movimiento, lo cual puede resultar muy atractivo en aplicaciones de rastreo.
Contenido
Región de exploración
- El tamaño de la región donde llevar a cabo la búsqueda es importante para dar con el bloque adecuado. Desgraciadamente, el coste computacional aumenta rápidamente (de forma casi cuadrática) con el incremento de esta ventana. Lo habitual es elegir una ventana de superficie ligeramente superior al máximo tamaño posible de los objetos móviles.
- Un campo de exploración pequeño supondrá que los vectores de desplazamiento encontrados serán también reducidos, lo cual resulta adecuado si se trabaja con secuencias de movimiento lento, además de reducir la computación necesaria.
- El número de píxeles que separa a los diferentes bloques candidatos que se quieren analizar dentro de la ventana se corresponde con la longitud del paso de búsqueda. Si esa longitud es igual a un píxel, significa que estamos realizando una búsqueda exhaustiva o Full Search. Si de lo contrario optamos por un paso mayor, incrementamos la velocidad del proceso al reducir el número de candidatos, pero incrementamos el error de estimación del vector.
Elección de bloque
Especifica la posición, el tamaño, la ubicación del inicio de búsqueda y la escala de los bloques con los que actuará el algoritmo.
- Elegir el tamaño correcto de los bloques no es trivial. Generalmente, los bloques mayores son menos sensibles al ruido, mientras que un bloque de dimensiones reducidas presenta unos contornos más bien definidos. El principal factor a la hora de escoger las dimensiones es el tamaño de los objetos a rastrear. Otros factores a tener en cuenta son la cantidad de ruido que presenta la secuencia y la textura tanto de los objetos como del fondo.
- También aparece el denominado problema de apertura cuando se trabaja con objetos de color uniforme. Los bloques en el interior de dichos objetos no parecen estar moviéndose porque todos los que le rodean son del mismo color. Un tamaño de bloque superior puede ser escogido para paliar este problema.
- La mayoría de los algoritmos de block matching utilizan el origen de la ventana de exploración como el centro inicial de búsqueda y no explotan la correlación entre los bloques pertenecientes a un mismo objeto de la imagen en movimiento. Para mejorar la precisión se podría hacer uso de dicha correlación con el fin de predecir una posición inicial que reflejase la tendencia de movimiento del bloque, permitiendo así encontrar su vector de movimiento óptimo de forma más eficiente.
- En gran parte de los métodos de búsqueda recientes, la dirección de los vectores de movimiento de los bloques elegidos determinan la ubicación del punto de inicio de la siguiente búsqueda.
Criterio de comparación
Para exponer los distintos criterios de semejanza, representados por C(x,y), tomaremos un macrobloque cuadrado de dimensiones n x n. Se medirá la diferencia entre un bloque del fotograma actual (Fa) y uno del de referencia (Fr), con un vector de desplazamiento (x,y).
- Sumatorio de diferencias absolutas (Sum of Absolute Differences, SAD):
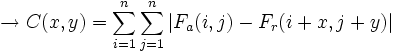
- Sumatorio de diferencias al cuadrado (Sum of Squared Differences, SSD):
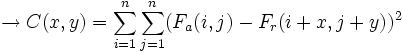
- Error absoluto medio (Mean Absolute Error, MAE):
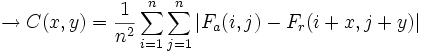
- Error cuadrático medio (Mean Squared Error, MSE):
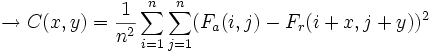
Otros criterios que tienen un uso extendido son la Correlación cruzada normalizada (Normalized Cross Correlation, NCC), la Clasificación por diferencia de píxel (Pixel Difference Classification, PDC), la Proyección integral o el MPC (que se basa en ponderar cada una de las diferencias según un umbral elegido).
Método de búsqueda
Estrategias inteligentes que especifiquen dónde buscar a posibles bloques candidatos pueden reducir la computación necesaria considerablemente.
Búsqueda exhaustiva o Full Search (FS)
Es el mejor y más simple procedimiento de exploración. Realiza una comparación exhaustiva con todos los bloques que se hallan en el interior de la ventana de búsqueda, encontrando así los vectores de movimiento óptimos.
Debido al alto coste computacional requerido por este método (demasiado elevado para aplicaciones en tiempo real), a lo largo de las últimas dos décadas se han desarrollado una gran variedad de algoritmos para obtener una estimación mucho más rápida con una distorsión de bloque similar.
Para reducir el número de operaciones, se puede optar tanto por disminuir el número de posibles candidatos como reducir los cálculos necesarios para cada uno de ellos. Los más destacados son descritos a continuación por orden cronológico de aparición.
Búsqueda en 3 pasos (3SS)
 Búsqueda en 3 pasos
Búsqueda en 3 pasos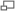
 Logarítmica en 2D
Logarítmica en 2D Búsqueda ortogonal
Búsqueda ortogonal Búsqueda cruzada
Búsqueda cruzada Búsqueda en espiral
Búsqueda en espiral Búsqueda en 4 pasos
Búsqueda en 4 pasos
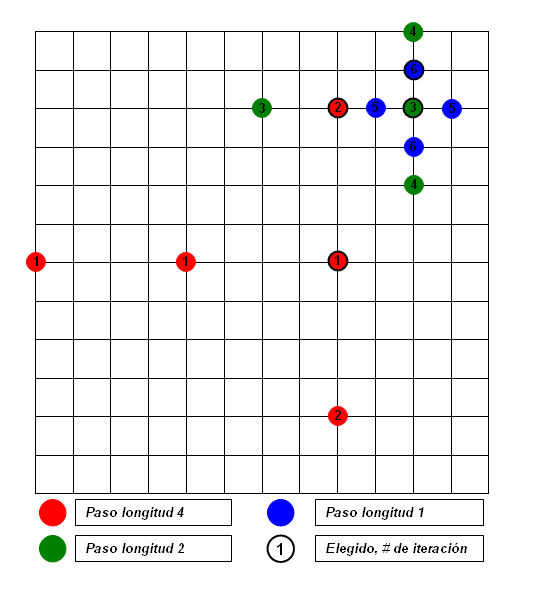
Aunque fue diseñado en 1981, se ha convertido en uno de los métodos más populares por su simplicidad y su alto rendimiento.En primer lugar, se elige la longitud del paso de búsqueda. Desde el centro, se comparan los ocho bloques situados en los puntos cardinales a la distancia de un paso y se escoge uno en función de alguno de los criterios comentados anteriormente. A continuación, se reduce la longitud del paso a la mitad, y desde el nuevo centro se vuelven a cotejar ocho bloques. Por último, se reduce de nuevo el paso (hasta valer 1 píxel) y se repite el proceso de nuevo.
Búsqueda logarítmica en 2D (TDL)
Algoritmo también diseñado en 1981 y muy parecido al anterior. Consiste en una búsqueda distribuida en etapas donde se va reduciendo la ventana sucesivamente hasta alcanzar el caso trivial. Aunque requiere más pasos que el 3SS, suele proporcionar mayor precisión, especialmente cuando la ventana de búsqueda es grande.
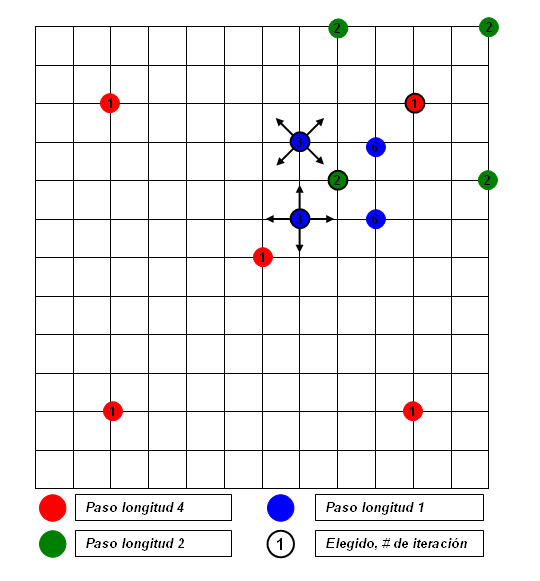
El bloque en el centro de la región de exploración y los cuatro candidatos a un paso de distancia situados en los ejes vertical y horizontal (formando una cruz en forma de ‘+’), son comparados con el bloque actual para determinar la mejor coincidencia. Si el bloque escogido es el del centro, la longitud del paso se reduce a la mitad; sino es así, el otro bloque escogido es el nuevo centro y se vuelve a iniciar el proceso. Cuando la longitud del paso llega a ser 1, los nueve bloques alrededor del centro son cotejados para hallar el requerido.
Algoritmo de búsqueda ortogonal (OSA)
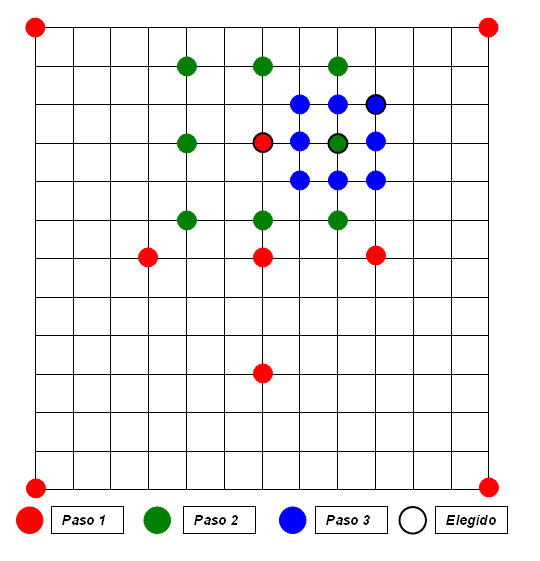
Método híbrido basado en el funcionamiento de los dos anteriores (3SS y TDL) e introducido en 1987. Después de elegir la longitud del paso (generalmente la mitad del desplazamiento máximo dentro de la ventana), se inicia con una etapa horizontal y otra vertical.
Se procede al análisis del bloque central y los dos candidatos a ambos lados del eje x, y el que obtiene un valor de distorsión menor se convierte en el centro de la siguiente fase vertical. Ahora son los dos bloques de encima y debajo, situados en el eje y, los que juntamente con el central son comparados, eligiendo de nuevo el centro de la etapa siguiente. Después de las iteraciones horizontal y vertical, la longitud del paso se reduce a la mitad (siempre que sea mayor que 1) y se repite el proceso nuevamente. Si fuera 1, se detiene y declara a una de las tres posiciones de la fase vertical como el bloque óptimo.
Algoritmo de búsqueda cruzada (CSA)
Este algoritmo, introducido en 1990, guarda una cierta similitud con el TDL. El proceso de exploración inicial es casi idéntico; la única diferencia es que los candidatos escogidos constituyen una cruz en forma de ‘x’ en lugar de ‘+’.
La longitud del paso de búsqueda se reduce a la mitad en cada iteración hasta que es igual a 1. En esa última etapa, si el candidato con mínima distorsión se halla en la posición inferior izquierda o superior derecha, la evaluación de los cuatro nuevos bloques seguirá una distribución en cruz ‘+’. De lo contrario, si el escogido se encuentra en el punto superior izquierdo o inferior derecho, la exploración será en forma de ‘x’.
Búsqueda en espiral (SS)
Propuesto en 1995, el método aquí expuesto busca combinar algunas ideas del 3SS con las de otros algoritmos, logrando acelerar los cálculos necesarios.
Al igual que en OSA, se toma como longitud del paso de búsqueda la mitad del desplazamiento máximo dentro de la ventana. A continuación, el punto de mínimo error se escoge de entre nueve bloques seleccionados del siguiente modo: cinco se toman de la cruz en forma de ‘+’ alrededor del centro, y los otros cuatro de cada una de las esquinas de la ventana. En la siguiente fase se reduce la longitud del paso y se sigue la misma filosofía (analizando los nueve puntos alrededor del de menor error), hasta que el paso se ve reducido a 1.
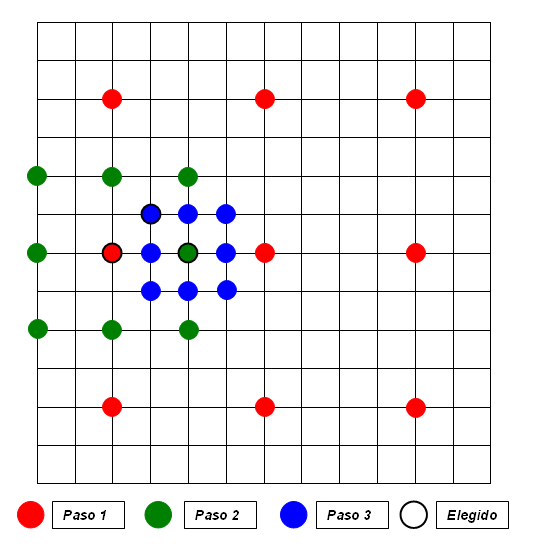
Búsqueda en 4 pasos (4SS)
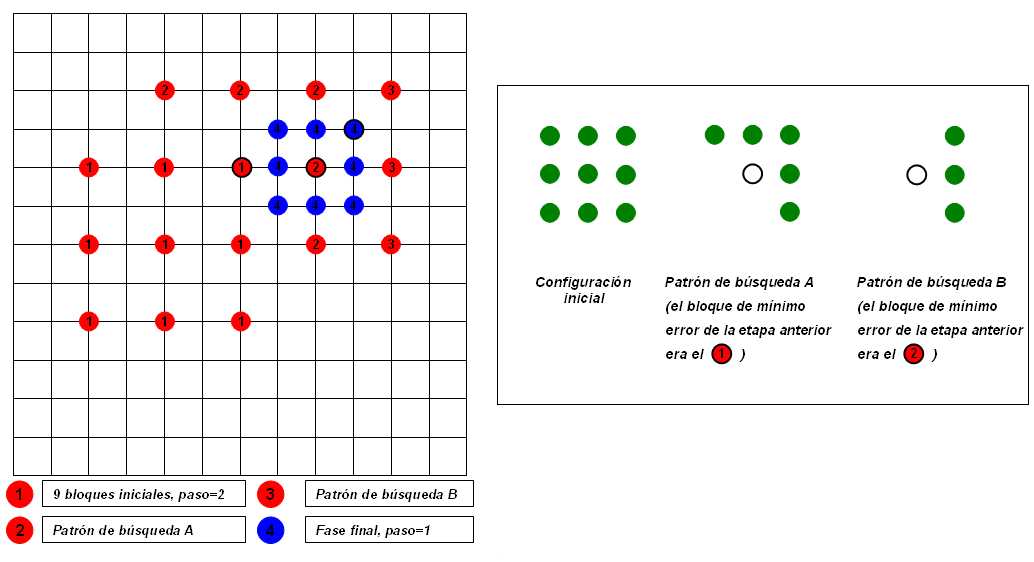
Este último algoritmo fue diseñado en 1996, y como sigue un funcionamiento algo complejo, se expondrá en cuatro puntos.
- 1.Para empezar se fija un paso de valor 2, y se toman nueve bloques alrededor del centro de la ventana. Se calcula el error correspondiente a cada uno para hallar al que presenta una distorsión menor. Si dicho bloque resulta ser el central, se siguen las instrucciones descritas en el punto 4. Si no lo es, se continúa con el punto 2.
- 2.Se desplaza el centro de la siguiente fase al bloque elegido, manteniendo la longitud del paso a 2. El patrón de búsqueda a seguir en el proceso dependerá de la posición del punto de mínimo error de la etapa previa.
- 3.Continuando con la misma estrategia de búsqueda, llegará un momento en que el punto escogido sea el central, pasando al punto 4 y final.
- 4.Se reduce la longitud del paso a 1 y se examinan los nueve bloques alrededor del centro para hallar, al fin, el óptimo.
Enlaces externos de interés
- Página Web oficial del IEEE
- Publicaciones recientes del IEEE
- Página Web oficial del MPEG
- Página Web oficial de la ITU
Véase también
Categorías: Algoritmos | Tecnología de vídeo y cine
Wikimedia foundation. 2010.