- Estimación de Movimiento
-
Estimación de Movimiento
Estimación de movimiento es el proceso a partir del cual se obtienen los vectores de movimiento (VM) de cada macrobloque (MB) de la imagen a codificar respeto una (o más) imágenes de referencia. La estimación de movimiento es una parte muy importante del proceso de codificación de vídeo y se utiliza en estándares y códecs tan populares como la familia de MPEG’s (MPEG-1, MPEG-2, MPEG-4), el último H.264/MPEG-4 AVC o el software libre Theora.
Contenido
Introducción
La codificación de vídeo pretende representar secuencias de imágenes con el menor número de bits posible. Por eso, los métodos de codificación de vídeo aplican tanto codificación Intraimagen como Interimagen. Con el primer tipo se intenta eliminar la redundancia espacial dentro de cada cuadro (frame), mientras que con la codificación Inter explotamos la redundancia temporal de la secuencia a codificar. La estimación y compensación de movimiento son los métodos que permiten este tipo de codificación.
La imagen se divide en bloques (a menudo cuadrados de unos cuántos píxeles, por ejemplo 4x4) y estos se agrupan formando MB. Cómo hemos dicho la estimación de movimiento nos permite obtener los VM de cada MB. La aplicación de estos vectores por crear la nueva imagen (imagen compensada) se denomina compensación de movimiento que, junto con el cálculo de la imagen error entre la imagen compensada y la imagen original que queremos codificar, es el que, en la gran mayoría de códecs, se envía al descodificador.
La estimación de movimiento es un proceso con una alta complejidad de cálculo y a menudo representa 2/3 del coste computacional en la codificación de vídeo. Como siempre, nos encontraremos con un compromiso de “Rate-distorcion”, es decir tiempo de procesado y medida fichero respecto calidad del vídeo comprimido. Esto hace que, actualmente, muchas de las investigaciones dentro el campo de la codificación de vídeo se centren en buscar algoritmos que puedan realizar más eficientemente la estimación de movimiento.
Backward vs. Forward
Es importante diferenciar entre estimación/compensación Backward y estimación/compensación Forward, así como entender porque los métodos de compresión de vídeo usan el primer caso. Esta clasificación diferencia en cuál de las dos imágenes (referencia y a codificar) se definen los MB de los cuales queremos buscar los vectores de movimiento que les corresponden.
Hablaremos de estimación Forward sí definimos los MB en la imagen referencia. Calculamos los VM a partir de la imagen referencia. Para cada MB de la imagen referencia buscamos dónde ha ido a parar en la imagen actual (a codificar) y, a partir de la nueva posición, extraemos los VM. Puede que algunos MB, o píxeles, de la imagen referencia no aparezcan en la original y que por lo tanto identificamos una misma zona de la imagen a codificar como la más parecida a más de un MB de la imagen referencia (1). Por generar la imagen compensada cogeremos cada MB de la de referencia y lo colocaremos en la nueva posición que le corresponde según los VM que hemos calculado. Si nos encontramos con (1) algunos píxeles de la imagen compensada se sobrescribirán y otros quedarán sin definir generando “agujeros”. Este problema no pasa si aplicamos estimación Backward, que define los MB en la imagen a codificar y busca dónde se encontraban (o se encontrarán) en la de referencia. Calculamos los VM a partir imagen actual. De esta manera, para llenar cada MB de la imagen compensada iremos a buscar dónde se encontraba en la imagen de referencia y copiaremos todos los píxeles. Aquí lo único que hacemos es llenar MB según los VM que hemos encontrado y por lo tanto no habrá ningún píxel sin definir. Es por esta razón que los estándares de codificación de vídeo utilizan la estimación Backward en lugar de la Forward.
 Esquema representativo estimación/compensación backward
Esquema representativo estimación/compensación backward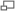
 Esquema representativo estimación/compensación fordward
Esquema representativo estimación/compensación fordwardAlgoritmos
Los estándares de codificación de vídeo definen cómo debe ser el bitstream de la señal codificada, pero no explican como se debe hacer para generarlo. Por lo tanto, existen multitud de codificadores de cada estándar que compiten entre sí para ver cuál de ellos es más eficiente.
Hay diferentes algoritmos por el cálculo de los VM , como hemos explicado se está investigando mucho sobre esto. Diferenciamos entre métodos de busca exhaustiva y métodos parciales, que ahorran tiempos de procesado a cambio de introducir más pérdidas en la secuencia final.
Block Matching
Block matching es el método más utilizado porque es el más fácil de implementar y el que consigue una mayor calidad. Por tal de simplificar el problema, asumimos:
- Movimiento sólo de translación (cambio de posición)
- Iluminación sin cambios
- Imagen sin oclusiones
Se trata de realizar una busca exhaustiva (“Full Search”, FS) píxel a píxel de la zona (de dimensiones iguales al MB) de la imagen referencia más parecida al MB que estamos considerando.
Hay diferentes métodos por encontrar el MB más parecido en la imagen referencia, pero en general se trata de buscar el mínimo entra la suma de las diferencias entre todos los píxeles de la imagen a codificar y de la de referencia dentro el MB que estamos considerando. En función de la diferencia entre la posición en la imagen actual y la posición en la imagen de referencia de un MB extraemos los VM que le corresponden.
Esta operación es tan costosa porque si por cada MB se buscara por toda la imagen (de dimensiones MxN y el MB fuera de BxB) se realizarían: (N-B+1)•(M-B+1)•2B operaciones para encontrar los VM de un solo MB, lo cual es del todo inviable para aplicaciones a tiempo real. Por esto siempre se utiliza una ventana de búsqueda de dimensiones 2Bx2B (el doble del MB) y sólo se busca el MB dentro de esta. De esta manera conseguimos reducir notablemente el número de operaciones, hasta (B+1)2•2B, para encontrar los VM de un MB y además conseguimos que este proceso no dependa de las dimensiones de la imagen.
Direccions Continuades
Este tipo de métodos calculan las diferencias en menos puntos. Hay una gran oferta de algoritmos que mejoran el coste computacional de la estimación de movimiento asumiendo que la función error (SAD) es convexa y sólo tiene un mínimo relativo dentro la ventana de búsqueda. Con esta simplificación, que se cumple muy a menudo, ya no hace falta que calculamos la SAD de todos los píxeles de la ventana, sino que empezaremos en un píxel determinado, nos miraremos los de su alrededor y nos moveremos por el gradiente más negativo.
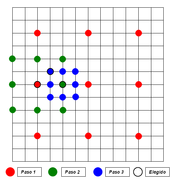 Ejemplo TTS
Ejemplo TTSLa diferencia de calidad entre la utilización de estos métodos y la búsqueda exhaustiva es prácticamente inapreciable. En función de qué punto es el primero que calculamos y qué nos miramos en cada iteración, encontramos los siguientes métodos:
- Búsqueda en 3 pasos (TSS)
- Búsqueda en 4 pasos (4SS)
- Búsqueda en Diamante (DS)
- Búsqueda logarítmica en 2D (TDL)
- Algoritmo de Búsqueda ortogonal (OSA)
- Búsqueda en espiral (SS)'
Distorsión Parcial
Dentro de este grupo encontramos los algoritmos que reducen el tiempo de procesado a partir de calcular menos diferencias cada vez que desplazamos el MB en la imagen de referencia. La idea es que si, en algún momento del cálculo de la SAD en una determinada posición, se supera el valor mínimo de la SAD total calculada en una posición anterior, podemos saltar al siguiente punto. La gracia de estos métodos es encontrar una SAD mínima lo antes posible porque cuanto antes encontremos el mínimo global en nuestra búsqueda, más rápido podremos descartar las SAD’s parciales de los otros candidatos. Estos métodos pueden introducir, o no, pérdidas en la secuencia generada, pero estas pérdidas resultan inapreciables.
- Búsqueda de Distorsión Parcial (PDS) (sin pérdidas)
- Búsqueda de Distorsión Parcial Normalizada (NPDS) (con pérdidas)
- Búsqueda de Distorsión Parcial basada en transformada Hadamard (HPDS) (sin pérdidas)
Aproximación Multiresolución
Otra manera de ahorrar tiempo es hacer la estimación de movimiento diezmando primero las dos imágenes. De esta manera tanto el tamaño del MB, como el de la ventana se habrán reducido. Habremos de buscar en menos puntos. A la hora de hacer la compensación, sí que utilizaremos las imágenes en las dimensiones originales y los VM que utilizaremos serán los obtenidos en la estimación, pero escalados. De Esta manera conseguimos reducir el tiempo de procesado a cambio de sufrir una pérdida de calidad, que puede resultar importante, en la imagen procesada, propia de cualquier proceso de diezmado-interpolación.
 Aplicamos estimación de movimento en las imágenes diezmadas
Aplicamos estimación de movimento en las imágenes diezmadasEnlaces
- Página Web oficial de la IEEE
- Publicaciones recientes de la IEEE
- Página Web oficial del MPEG
- Página Web oficial de la ITU
Categorías: Telecomunicaciones | Algoritmos



Wikimedia foundation. 2010.