- Máquinas de vectores de soporte
-
Las máquinas de soporte vectorial o máquinas de vectores de soporte (Support Vector Machines, SVMs) son un conjunto de algoritmos de aprendizaje supervisado desarrollados por Vladimir Vapnik y su equipo en los laboratorios AT&T.
Estos métodos están propiamente relacionados con problemas de clasificación y regresión. Dado un conjunto de ejemplos de entrenamiento (de muestras) podemos etiquetar las clases y entrenar una SVM para construir un modelo que prediga la clase de una nueva muestra. Intuitivamente, una SVM es un modelo que representa a los puntos de muestra en el espacio, separando las clases por un espacio lo más amplio posible. Cuando las nuevas muestras se ponen en correspondencia con dicho modelo, en función de su proximidad pueden ser clasificadas a una u otra clase.
Más formalmente, una SVM construye un hiperplano o conjunto de hiperplanos en un espacio de dimensionalidad muy alta (o incluso infinita) que puede ser utilizado en problemas de clasificación o regresión. Una buena separación entre las clases permitirá un clasificación correcta.
Contenido
Idea básica
Dado un conjunto de puntos, subconjunto de un conjunto mayor (espacio), en el que cada uno de ellos pertenece a una de dos posibles categorías, un algoritmo basado en SVM construye un modelo capaz de predecir si un punto nuevo (cuya categoría desconocemos) pertenece a una categoría o a la otra.
Como en la mayoría de los métodos de clasificación supervisada, los datos de entrada (los puntos) son vistos como un vector p-dimensional (una lista de p números).
La SVM busca un hiperplano que separe de forma óptima a los puntos de una clase de la de otra, que eventualmente han podido ser previamente proyectados a un espacio de dimensionalidad superior.
En ese concepto de "separación óptima" es donde reside la característica fundamental de las SVM: este tipo de algoritmos buscan el hiperplano que tenga la máxima distancia (margen) con los puntos que estén más cerca de él mismo. Por eso también a veces se les conoce a las SVM como clasificadores de margen máximo. De esta forma, los puntos del vector que se etiquetados con una categoría estarán a un lado del hiperplano y los casos que se encuentren en la otra categoría estarán al otro lado.
Los algoritmos SVM pertenecen a la familia de los clasificadores lineales. También pueden ser considerados un caso especial de la regularización de Tikhonov.
En la literatura de los SVMs, se llama atributo a la variable predictora y característica a un atributo transformado que es usado para definir el hiperplano. La elección de la representación más adecuada del universo estudiado, se realiza mediante un proceso denominado selección de características.
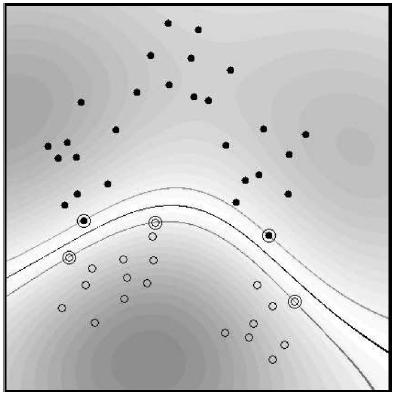
Al vector formado por los puntos más cercanos al hiperplano se le llama vector de soporte.
Los modelos basados en SVMs están estrechamente relacionados con las redes neuronales. Usando una función kernel, resultan un método de entrenamiento alternativo para clasificadores polinomiales, funciones de base radial y perceptrón multicapa.
Ejemplo en 2–dimensiones
En el siguiente ejemplo idealizado para 2-dimensiones, la representación de los datos a clasificar se realiza en el plano x-y. El algoritmo SVM trata de encontrar un hiperplano 1-dimensional (en el ejemplo que nos ocupa es una línea) que une a las variables predictoras y constituye el límite que define si un elemento de entrada pertenece a una categoría o a la otra.
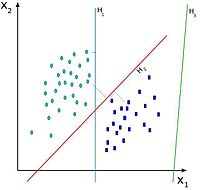
Existe un número infinito de posibles hiperplanos (líneas) que realicen la clasificación pero, ¿cuál es la mejor y cómo la definimos?
La mejor solución es aquella que permita un margen máximo entre los elementos de las dos categorías.
Hay infinitos hiperplanos posiblesSe denominan vectores de soporte a los puntos que conforman las dos líneas paralelas al hiperplano, siendo la distancia entre ellas (margen) la mayor posible.
Soft margin: Errores de entrenamiento
Idealmente, el modelo basado en SVM debería producir un hiperplano que separe completamente los datos del universo estudiado en dos categorías. Sin embargo, una separación perfecta no siempre es posible y, si lo es, el resultado del modelo no puede ser generalizado para otros datos. Esto se conoce como sobreajuste (overfitting).
Con el fin de permitir cierta flexibilidad, los SVM manejan un parámetro C que controla la compensación entre errores de entrenamiento y los márgenes rígidos, creando así un margen blando (soft margin) que permita algunos errores en la clasificación a la vez que los penaliza.
Función Kernel
La manera más simple de realizar la separación es mediante una línea recta, un plano recto o un hiperplano N-dimensional.
Desafortunadamente los universos a estudiar no se suelen presentar en casos idílicos de dos dimensiones como en el ejemplo anterior, sino que un algoritmo SVM debe tratar con a) más de dos variables predictoras, b) curvas no lineales de separación, c) casos donde los conjuntos de datos no pueden ser completamente separados, d) clasificaciones en más de dos categorías.
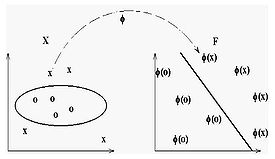
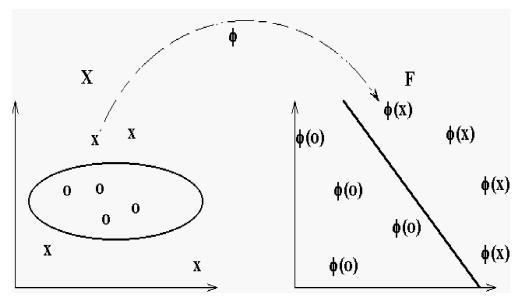
Debido a las limitaciones computacionales de las máquinas de aprendizaje lineal, éstas no pueden ser utilizadas en la mayoría de las aplicaciones del mundo real. La representación por medio de funciones Kernel ofrece una solución a este problema, proyectando la información a un espacio de características de mayor dimensión el cual aumenta la capacidad computacional de la máquinas de aprendizaje lineal. Es decir, mapearemos el espacio de entradas X a un nuevo espacio de características de mayor dimensionalidad (Hilbert):
-
-
- F = {φ(x)|x ∈ X}
-
-
-
-
- x = {x1, x2, · · · , xn} → φ(x) = {φ(x)1, φ(x)2, · · · , φ(x)n}
-
-
Tipos de funciones Kernel (Núcleo)
- Polinomial-homogénea: K(xi, xj) = (xi·xj)n
- Perceptron: K(xi, xj)= || xi-xj ||
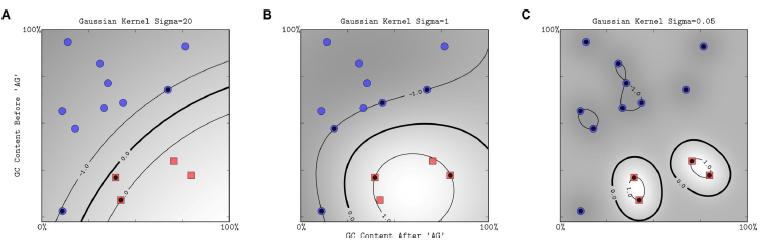
- Función de base radial Gaussiana: separado por un hiperplano en el espacio transformado.
-
-
- K(xi, xj)=exp(-(xi-xj)2/2(sigma)2)
-

- Sigmoid: K(xi, xj)=tanh(xi· xj−θ)
SVR. Regresión
Una nueva versión de SVM para regresión fue propuesta en 1996 por Vladimir Vapnik, Harris Drucker, Chris Burges, Linda Kaufman y Alex Smola.[nota].
La idea básica de SVR consiste en realizar un mapeo de los datos de entrenamiento x ∈ X, a un espacio de mayor dimensión F a través de un mapeo no lineal φ : X → F , donde podemos realizar una regresión lineal.
SVM Multiclase
Hay dos filosofías básicas para resolver el problema de querer clasificar los datos en más de dos categorías:
- a) cada categoría es dividida en otras y todas son combinadas.
- b) se contruyen k(k-1) / 2 modelos donde k es el número de categorías.
Comparativa SVM vs ANN
La siguiente tabla muestra una comparativa entre las redes neuronales artificales y los algoritmos SVM.

Enlaces externos
- (en inglés) [1], DTREG, Software For Predictive Modeling and Forecasting
- (en inglés) [2], Electronic Statistics Textbook
- (pdf) [3], curso sobre decisión, estimación y clasificación.
- (en inglés) www.kernel-machines.org, información general y material de investigación.
- (en inglés) www.support-vector.net, novedades, enlace y códigos relacionados con las máquinas de soporte vectorial.
- (en inglés) SVM light, implementación de SVM, con variantes para aprendizaje supervisado, y para semisupervisado transductivo. Liberado para investigación.
- (en inglés) SVMlin, otra implementación de SVM. Liberado bajo licencia GPL.
Categorías:- Redes neuronales artificiales
- Algoritmos de clasificación
- Aprendizaje automático
-

Wikimedia foundation. 2010.