- Algoritmo de búsqueda A*
-
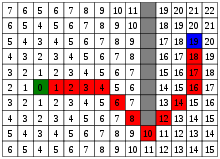 Ejemplo de aplicación del algoritmo A*.
Ejemplo de aplicación del algoritmo A*.
El algoritmo de búsqueda A* (pronunciado "A asterisco" o "A estrella") se clasifica dentro de los algoritmos de búsqueda en grafos. Presentado por primera vez en 1968 por Peter E. Hart, Nils J. Nilsson y Bertram Raphael, el algoritmo A* encuentra, siempre y cuando se cumplan unas determinadas condiciones, el camino de menor coste entre un nodo origen y uno objetivo.
Contenido
Motivación y descripción
El problema de algunos algoritmos de búsqueda en grafos informados, como puede ser el algoritmo voraz, es que se guían en exclusiva por la función heurística, la cual puede no indicar el camino de coste más bajo, o por el coste real de desplazarse de un nodo a otro (como los algoritmos de escalada), pudiéndose dar el caso de que sea necesario realizar un movimiento de coste mayor para alcanzar la solución. Es por ello bastante intuitivo el hecho de que un buen algoritmo de búsqueda informada debería tener en cuenta ambos factores, el valor heurístico de los nodos y el coste real del recorrido.
Así, el algoritmo A* utiliza una función de evaluación f(n) = g(n) + h'(n), donde h'(n) representa el valor heurístico del nodo a evaluar desde el actual, n, hasta el final, y g(n), el coste real del camino recorrido para llegar a dicho nodo, n. A* mantiene dos estructuras de datos auxiliares, que podemos denominar abiertos, implementado como una cola de prioridad (ordenada por el valor f(n) de cada nodo), y cerrados, donde se guarda la información de los nodos que ya han sido visitados. En cada paso del algoritmo, se expande el nodo que esté primero en abiertos, y en caso de que no sea un nodo objetivo, calcula la f(n) de todos sus hijos, los inserta en abiertos, y pasa el nodo evaluado a cerrados.
El algoritmo es una combinación entre búsquedas del tipo primero en anchura con primero en profundidad: mientras que h'(n) tiende a primero en profundidad, g(n) tiende a primero en anchura. De este modo, se cambia de camino de búsqueda cada vez que existen nodos más prometedores.
Propiedades
Como todo algoritmo de búsqueda en anchura, A* es un algoritmo completo: en caso de existir una solución, siempre dará con ella.
Si para todo nodo n del grafo se cumple g(n) = 0, nos encontramos ante una búsqueda voraz. Si para todo nodo n del grafo se cumple h(n) = 0, A* pasa a ser una búsqueda de coste uniforme no informada.
Para garantizar la optimalidad del algoritmo, la función h(n) debe ser admisible, esto es, que no sobrestime el coste real de alcanzar el nodo objetivo.
De no cumplirse dicha condición, el algoritmo pasa a denominarse simplemente A, y a pesar de seguir siendo completo, no se asegura que el resultado obtenido sea el camino de coste mínimo. Asimismo, si garantizamos que h(n) es consistente (o monótona), es decir, que para cualquier nodo n y cualquiera de sus sucesores, el coste estimado de alcanzar el objetivo desde n no es mayor que el de alcanzar el sucesor más el coste de alcanzar el objetivo desde el sucesor.
Complejidad computacional
La complejidad computacional del algoritmo está íntimamente relacionada con la calidad de la heurística que se utilice en el problema. En el caso peor, con una heurística de pésima calidad, la complejidad será exponencial, mientras que en el caso mejor, con una buena h'(n), el algoritmo se ejecutará en tiempo lineal. Para que esto último suceda, se debe cumplir que
donde h* es una heurística óptima para el problema, como por ejemplo, el coste real de alcanzar el objetivo.
Complejidad en memoria
El espacio requerido por A* para ser ejecutado es su mayor problema. Dado que tiene que almacenar todos los posibles siguientes nodos de cada estado, la cantidad de memoria que requerirá será exponencial con respecto al tamaño del problema. Para solucionar este problema, se han propuesto diversas variaciones de este algoritmo, como pueden ser RTA*, IDA* o SMA*.
Implementación en pseudocódigo
Tratar punto
.:= . // coste del camino hasta . caso . = . perteneciente a () si g(.) < g(.) entonces // (-----) // nos quedamos con el camino de menor coste .:= MEJORNODO actualizar g(.) y f'(.) propagar g a . de . eliminar . añadir . a ._MEJORNODO caso . = . perteneciente a )-----( si g(.) < g(.) entonces // nos quedamos con el camino de menor coste .:= MEJORNODO actualizar g(.) y f'(.) eliminar . añadir . a ._MEJORNODO caso . no estaba en ).( ni (.) añadir . a ).( añadir . a ._MEJORNODO f'(.) := g(.) + h'(.)Implementación en pseudocódigo
ABIERTOS := [INICIAL] //inicialización CERRADOS := [] f'(INICIAL) := h'(INICIAL) repetir si ABIERTOS = [] entonces FALLO si no // quedan nodos extraer MEJORNODO de ABIERTOS con f' mínima // cola de prioridad mover MEJORNODO de ABIERTOS a CERRADOS si MEJORNODO contiene estado_objetivo entonces SOLUCION_ENCONTRADA := TRUE si no generar SUCESORES de MEJORNODO para cada SUCESOR hacer TRATAR_SUCESOR hasta SOLUCION_ENCONTRADA o FALLO
TRATAR_SUCESOR
SUCESOR.ANTERIOR := VIEJO // coste del camino hasta SUCESOR caso SUCESOR = VIEJO perteneciente a CERRADOS si g(SUCESOR) < g(VIEJO) entonces // (no si monotonía) // nos quedamos con el camino de menor coste VIEJO.ANTERIOR := MEJORNODO actualizar g(VIEJO) y f'(VIEJO) propagar g a sucesores de VIEJO eliminar SUCESOR añadir VIEJO a SUCESORES_MEJORNODO caso SUCESOR = VIEJO perteneciente a ABIERTOS si g(SUCESOR) < g(VIEJO) entonces // nos quedamos con el camino de menor coste VIEJO.ANTERIOR := MEJORNODO actualizar g(VIEJO) y f'(VIEJO) eliminar SUCESOR añadir VIEJO a SUCESORES_MEJORNODO caso SUCESOR no estaba en ABIERTOS ni CERRADOS añadir SUCESOR a ABIERTOS añadir SUCESOR a SUCESORES_MEJORNODO f'(SUCESOR) := g(SUCESOR) + h'(SUCESOR)
Observaciones
Como se mencionó anteriormente h'(x) es un estimador de h(x) que informa la distancia al nodo objetivo, entonces
Si h'(x) hace un estimación perfecta de h(x), A* converge inmediatamente al objetivo.
Si h'(x) = 0, la función g(x) controla la búsqueda.
Si h'(x) = 0 y g(x) =0 la búsqueda será aleatoria.
Si h'(x) = 0 y g(x) =1 o constante la búsqueda será Primero en Anchura.
Si h'(x) nunca sobrestima a h(x) (o subestima), se garantiza encontrar el camino optimo, pero se desperdicia esfuerzo explorando otras rutas que parecieron buenas.
Si h'(x) sobrestima a h(x), no puede garantizarse la consecución del camino del menor coste
Enlaces externos
Programa que ilustra el funcionamiento de varios algoritmos de busqueda.
 Wikimedia Commons alberga contenido multimedia sobre Algoritmo de búsqueda A*Commons.
Wikimedia Commons alberga contenido multimedia sobre Algoritmo de búsqueda A*Commons.
Categorías:- Algoritmos de búsqueda
- Algoritmos de grafos
- Árboles (estructura)


Wikimedia foundation. 2010.