- Reconocimiento de patrones
-
El reconocimiento de patrones es la ciencia que se ocupa de los procesos sobre ingeniería, computación y matemáticas relacionados con objetos físicos o abstractos, con el propósito de extraer información que permita establecer propiedades de entre conjuntos de dichos objetos.
Contenido
Introducción
Al Reconocimiento de patrones llamado también lectura de patrones, identificación de figuras y reconocimiento de formas[1] consiste en el reconocimiento de patrones de señales. Los patrones se obtienen a partir de los procesos de segmentación, extracción de características y descripción dónde cada objeto queda representado por una colección de descriptores. El sistema de reconocimiento debe asignar a cada objeto su categoría o clase (conjunto de entidades que comparten alguna característica que las diferencia del resto). Para poder reconocer los patrones se siguen los siguientes procesos:
- adquisición de datos
- extracción de características
- toma de decisiones
El punto esencial del reconocimiento de patrones es la clasificación: se quiere clasificar una señal dependiendo de sus características. Señales, características y clases pueden ser de cualquiera forma, por ejemplo se puede clasificar imágenes digitales de letras en las clases «A» a «Z» dependiendo de sus píxeles o se puede clasificar ruidos de cantos de los pájaros en clases de órdenes aviares dependiendo de las frecuencias.

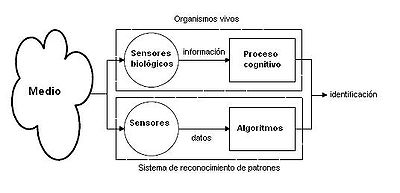
Sistema básico de reconocimiento
Un sistema completo de reconocimiento de patrones incluye un sensor que recoja fielmente los elementos del universo a ser clasificado, un mecanismo de extracción de características cuyo propósito es extraer la información útil, eliminando la información redundante e irrelevante, y finalmente una etapa de toma de decisiones en la cual se asigna a la categoría apropiada los patrones de clase desconocida a priori.
Sensor
El sensor es el dispositivo encargado de la adquisición de datos. Ha de ser capaz de transformar magnitudes físicas o químicas, llamadas variables de instrumentación, en magnitudes eléctricas. Las variables de instrumentación dependen del tipo de sensor y pueden ser por ejemplo: temperatura, intensidad lumínica, distancia, aceleración, inclinación, desplazamiento, presión, fuerza, torsión, humedad, etc.
Extracción de características
Es el proceso de generar características que puedan ser usadas en el proceso de clasificación de los datos. En ocasiones viene precedido por un preprocesado de la señal, necesario para corregir posibles deficiencias en los datos debido a errores del sensor, o bien para preparar los datos de cara a posteriores procesos en las etapas de extracción de características o clasificación.
Las características elementales están explícitamente presentes en los datos adquiridos y pueden ser pasados directamente a la etapa de clasificación. Las características de alto orden son derivadas de las elementales y son generadas por manipulaciones o transformaciones en los datos.
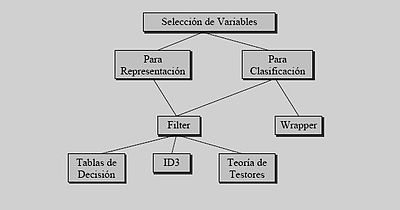
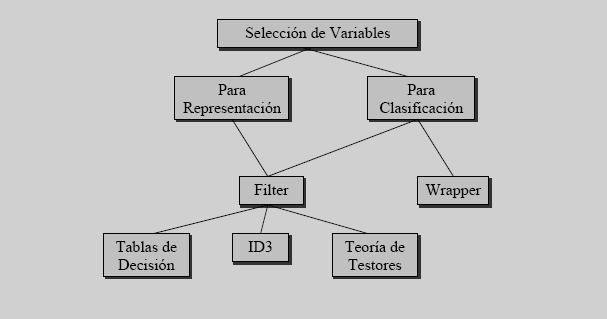
Selección de variables
Consiste en seleccionar cuál es el tipo de características o rasgos más adecuados para describir los objetos. Para ello, se deben localizar los rasgos que inciden en el problema de manera determinante.
Esta etapa también puede ser diseñada dentro de la clasificación.
La selección de variables puede diferenciarse según los objetivos buscados:
-
- Para la clasificación: la selección de características relevantes, a partir del conjunto total de características que describen a los objetos, se hace con dos motivos fundamentales: mejorar la clasificación o aumentar la velocidad de procesamiento.
- Para la representación: decidir qué características representan mejor a cierto tipo de objetos.
Estrategias de selección de variables:
-
- wrapper: la selección de características se hace usando información del mecanismo de clasificación.
- filter: la selección se hace con un criterio independiente del clasificador. Incluye algunos métodos como:
-
- Tablas de decisión: le busca un subconjunto mínimo de variables que no introduzca confusión entre clases.
- ID3: le crea un árbol de decisión y se selecciona un conjunto de variables que permita discriminar entre clases.
- Teoría de testores: le buscan todos los subconjuntos de variables discriminantes minimales, con estos se evalúa la relevancia de cada variable y se seleccionan aquellas con mayor relevancia.
Clasificación
La clasificación trata de asignar las diferentes partes del vector de características a grupos o clases, basándose en las características extraídas. En esta etapa se usa lo que se conoce como aprendizaje automático, cuyo objetivo es desarrollar técnicas que permitan a las computadoras aprender.
Utiliza habitualmente uno de los siguientes procedimientos:
-
- Geométrico (Clustering): Los patrones deben ser graficables. En éste enfoque se emplea el cálculo de distancias, geometría de formas, vectores numéricos, puntos de atracción, etc.
-
- Estadístico: Se basa en la teoría de la probabilidad y la estadística, utiliza análisis de varianzas, covarianzas, dispersión, distribución, etc.
Supone que se tiene un conjunto de medidas numéricas con distribuciones de probabilidad conocidas y a partir de ellas se hace el reconocimiento.
-
- Sintáctico‐estructural: se basa en encontrar las relaciones estructurales que guardan los objetos de estudio, utilizando la teoría de lenguajes formales, teoría de autómatas, etc. El objetivo es construir una gramática que describa la estructura del universo de objetos.
-
- Neuro‐reticular: se utilizan redes neuronales que se ‘entrenan’ para dar una cierta respuesta ante determinados valores.
-
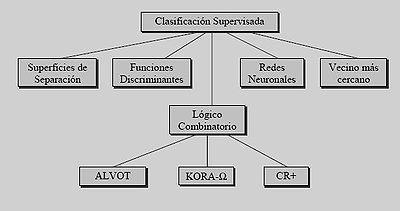
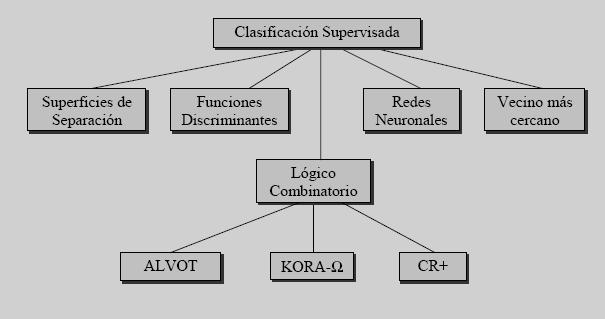
- Lógico‐combinatorio: se basa en la idea de que el modelado del problema debe ser lo más cercano posible a la realidad del mismo, sin hacer suposiciones que no estén fundamentadas. Se utiliza para conjuntos difusos y utiliza lógica simbólica, circuitos combinacionales y secuenciales, etc.
Según tengamos constancia o no de un conjunto previo que permita al sistema aprender, la clasificación pueder ser supervisada, parcialemente supervisada o no supervisada.
-
- a) Clasificación supervisada: también es conocida como clasificación con aprendizaje. Se basa en la disponibilidad de áreas de entrenamiento. Se trata de áreas de las que se conoce a priori la clase a la que pertenecen y que servirán para generar una signatura espectral característica de cada una de las clases. Se denominan clases informacionales en contraposición a las clases espectrales que genera la clasificación no supervisada.
-
- Algunos métodos de la clasificación supervisada:
-
- Funciones discriminantes: si son dos clases, se busca obtener una función g tal que para un nuevo objeto O, si g(O) ≥ 0 se asigna a la clase 1 y en otro caso a la 2. Si son múltiples clases se busca un conjunto de funciones gi y el nuevo objeto se ubica en la clase donde la función tome el mayor valor.
- Vecino más cercano: un nuevo objeto se ubica en la clase donde esté el objeto de la muestra original que más se le parece.
- Redes neuronales artificiales: denominadas habitualmente RNA o en sus siglas en inglés ANN. Se supone que imitan a las redes neuronales reales en el desarrollo de tareas de aprendizaje.
-
- Algunos métodos de la clasificación supervisada:
-
- b) Clasificación parcialmente supervisada: también conocida como de aprendizaje parcial. En éstos problemas existe una muestra de objetos sólo en algunas de las clases definidas.
-
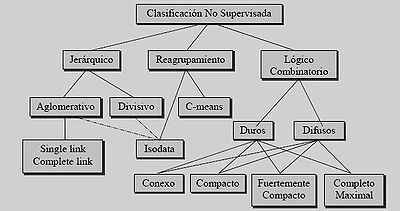
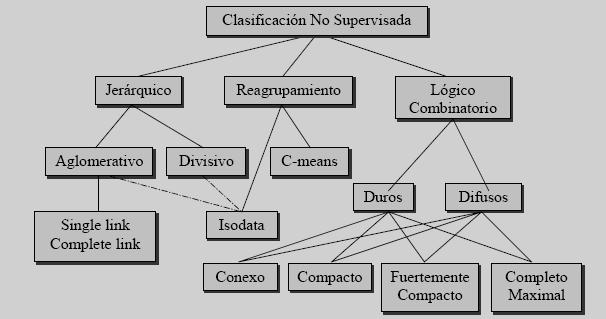
- c) Clasificación no supervisada: también conocida como clasificación sin aprendizaje. Se utilizan algoritmos de clasificación automática multivariante en los que los individuos más próximos se van agrupando formando clases.
-
- Restringida: el número de clases en la que se estructurará la muestra está previamente definido.
- Libre: el número de clases en la que se estructurará la muestra depende exclusivamente de los datos.
-
- c) Clasificación no supervisada: también conocida como clasificación sin aprendizaje. Se utilizan algoritmos de clasificación automática multivariante en los que los individuos más próximos se van agrupando formando clases.
-
- Algunos métodos de la clasificación no supervisada:
-
- Simple Link y Complete Link: parten de grupos unitarios de objetos y van uniendo los grupos más parecidos en cada etapa, hasta cumplir alguna condición.
- ISODATA: se van formando grupos que se ajustan iterativamente usando teoría de probabilidades. En alguna versiones se puede hacer la unión o división de algún grupo.
- C-means: se define un grupo de semillas, se asocia cada objeto al grupo de la semilla más parecida, se toman los centroides de cada grupo como nuevas semillas y se itera hasta que se estabilice.
- Criterios lógico-combinatorios: los criterios que se imponen a los grupos son tales como ser conexos, completos maximales, compactos, etc.
-
- Algunos métodos de la clasificación no supervisada:
El reconocimiento de patrones es más complejo cuando se usan plantillas para generara variantes. Por ejemplo, en castellano, las frases a menudo siguen el patrón "sujeto-predicado", pero se requiere cierto conocimiento de la lengua para detectar el patrón. El reconocimiento de patrones se estudia en muchos campos, incluyendo psicología, etología, informática y procesamiento digital de señales.Aplicaciones
Los sistemas de reconocimiento de patrones tienen diversas aplicaciones. Algunas de las más relevantes y utilizadas actualmente son:
- Previsión meteorológica: poder clasificas todos los datos meteorológicos según diversos patrones, con el conocimiento a pariori que tenemos de las diferentes situaciones que pueden aperecer nos permite crear mapas de predicción automática.
- Reconocimiento de caracteres escritos a mano o a máquina: es una de las utilidades más populares de los sistemas de reconocimiento de patrones ya que los símbolos de escritura son fácilmente identificables.
- Reconocimiento de voz: el análisis de la señal de voz se utiliza actualmente en muchas aplicaciones, un ejemplo claro son los teleoperadores informáticos.
- Aplicaciones en medicina: análisis de biorritmos, detección de irregularidades en imágenes de rayos-x, detección de células infectadas, marcas en la piel...
- Reconocimiento de huellas dactilares: utilizado y conocido por la gran mayoría, mediante las huellas dactilares todos somos identificables y con programas que detectan y clasifican las coincidencias, resulta sencillo encontrar correspondencias.
- Reconocimiento de caras: utilizado para contar asistentes en una manifestación o simplemente para detectar una sonrisa, ya hay diferentes cámaras en el mercado con esta opción disponible.
- Interpretación de fotografías aéreas y de satélite: gran utilidad para propuestas militares o civiles, como la agricultura, geología, geografía, planificación urbana...
- Predicción de magnitudes máximas de terremotos.
- Reconocimiento de objetos: con importantes aplicaciones para personas con discapacidad visual.
- Reconocimiento de música: identificar el tipo de música o la canción concreta que suena.
Notas y referencias
- ↑ Ernesto A. Meyer: Glosario de términos técnicos, Entrada P, «pattern recognition». Grupo de Informática Aplicada al Inglés Técnico, la Argentina, 1995, bajo la licencia de documentación libre GNU
Bibliografía
- Richard O. Duda, Peter E. Hart, David G. Stork (2001) Pattern classification (2ª edición), Wiley, New York, ISBN 0-471-05669-3.
- Dietrich Paulus and Joachim Hornegger (1998) Applied Pattern Recognition (2ª edición), Vieweg. ISBN 3-528-15558-2
- J. Schuermann: Pattern Classification: A Unified View of Statistical and Neural Approaches, Wiley&Sons, 1996, ISBN 0-471-13534-8
- Sholom Weiss and Casimir Kulikowski (1991) Computer Systems That Learn, Morgan Kaufmann. ISBN 1-55860-065-5
Enlaces externos
- Lista de webs sobre reconocimiento de patrones
- Journal of Pattern Recognition Research
- Recuperación y Extracción de la información no supervisada
- Extracción de Información con Clasificación Supervisada
- Librería virtual de artículos sobre reconocimiento de patrones
- Notas del seminario de Reconocimiento de Patrones de Grupo de Tratamiento de Imágenes del Instituto de Ingeniería Eléctrica. Univ. de Surrey
- The Neural Approach to Pattern Recognition
- Laboratorio de cómputo de la Universidad La Salle de México
- Ejemplo de algoritmo capaz de reconocer patrones (OCR básico) escrito en Java y de licencia GPL


Wikimedia foundation. 2010.