- Lexical Markup Framework
-
El Lexical Markup Framework (LMF) es un proyecto en fase de desarrollo de la Organización Internacional para la Estandarización ISO/TC37 con el fin de definir un marco común normalizado para la construcción de lexicones y diccionarios máquina (MRD) para el Procesamiento del lenguaje natural (PLN). El alcance del proyecto es la normalización de principios y métodos relacionados con los recursos lingüísticos en el contexto de la comunicación multilingüe y de la diversidad cultural.
Contenido
Objetivos del LMF
El LMF se propone proporcionar un modelo común para la creación y uso de recursos léxicos, gestionar el intercambio de datos entre dichos recursos, y permitir la combinación de grandes cantidades de recursos individuales para formar recursos electrónicos globales y amplios.
Los tipos de instanciaciones individuales del LMF pueden incluir recursos léxicos monolingües, bilingües o multilingües. Las mismas especificaciones se usan para lexicones grandes y pequeños, tanto para lexicones simples como complejos, y para representaciones léxicas escritas o habladas. Las descripciones van desde la morfología lingüística, sintaxis, semántica computacional hasta la traducción asistida por ordenador. Las lenguas cubiertas no están restringidas a las lenguas europeas sino que abarca toda lengua natural. El rango de su aplicación al PLN no está restringido. El LMF puede representar la mayoría de lexicones, incluyendo los lexicones WordNet, EDR y PAROLE.
Historia del LMF
En el pasado, la normalización de lexicones se estudió y desarrolló mediante una serie de proyectos como GENELEX, EDR, EAGLES, MULTEXT, PAROLE, SIMPLE e ISLE. Luego, las delegaciones nacionales de ISO/TC37 decidieron abordar normas dedicadas al PLN y la representación de lexicones. El desarrollo del LMF inició en el verano de 2003 por una propuesta para un nuevo item emitida por la delegación de los EUA. En el otoño de 2003, la delegación francesa emitió una propuesta técnica para un modelo de datos destinado a los lexicones para PLN. A comienzos de 2004, el comité ISO/TC37 decidió formar un proyecto ISO común junto con Nicoletta Calzolari (Italia) como coordinadora y Gil Francopoulo (Francia) y Monte George (EUA) como editores. Desde esa fecha, se han escrito 13 versiones que se han enviado a los expertos nacionales nombrados. Estas versiones se han comentado y discutido en varias reuniones técnicas de la ISO.
Etapa actual
El número ISO es 24613. La especificación LMF ha sido publicada oficialmente como un estándar internacional el 17 de noviembre de 2008.
LMF como miembro de las normas de la familia ISO/TC37
Las normas ISO/TC37 se elaboran actualmente como especificaciones de alto nivel y tratan de la segmentación de palabras (ISO 24614), anotaciones (ISO 24611 también conocida como MAF, ISO 24612 ó LAF, ISO 24615 ó SynAF, e ISO 24617-1 ó SemAF/Time), estructuras de rasgos (ISO 24610), contenedores multimedia (ISO 24616 ó MLIF), y lexicones (ISO 24613). Estas normas se basan en especificaciones de bajo nivel dedicadas a constantes, es decir categorías de datos (revisión de la norma ISO 12620), código de lenguas (ISO 639), código de escritura (ISO 15924), códigos de países (ISO 3166) y Unicode (ISO 10646).
La organización de dos niveles forma una familia coherente de normas con las siguientes reglas comunes y simples:
- la especificación de alto nivel proporciona elementos estructurales que se adornan con constantes normalizadas;
- la especificación de bajo nivel proporciona constantes normalizadas como metadatos.
Normas clave empleadas por el LMF
Las constantes lingüísticas como /femenino/ o /transitivo/ no se definen dentro del LMF sino que se registran en el Data Category Registry (DCR) (Registro de categorías de datos) que es mantenido como un recurso global por parte del ISO/TC37 de conformidad con la norma ISO/IEC 11179-3:2003 [1]. Estas constantes se usan para adornar los elementos estructurales de alto nivel.
La especificación LMF cumple con los principios de modelación del Lenguaje Unificado de Modelado (UML) según lo define el Grupo de Gestión de Objetos (OMG, por sus siglas en inglés). La estructura se especifica mediante la clase UML#Diagramas. Los ejemplos se presentan por medio de diagramas de instancias UML (u objetos).
Adicionalmente, en un anexo al documento XML se presenta una definición de tipo de documento DTD.
Estructura modelo
El LMF comprende los siguientes componentes:
- El paquete principal como esqueleto estructural que describe la jerarquía básica de información en una entrada léxica.
- Extensiones al paquete principal que se expresan en un marco que describe la reutilización de los componentes principales junto con los componentes adicionales requeridos para un recurso léxico específico.
Las extensiones se dedican específicamente a la morfología, diccionarios máquina, sintaxis con PLN, semántica con PLN, notaciones multilingües con PLN, patrones de paradigmas con PLN, patrones de expresiones multipalabra, y patrones de expresiones restringidas.
Un pequeño ejemplo
En el siguiente ejemplo, la entrada léxica está asociada con un lema clergyman y dos formas flexionadas clergyman y clergymen. La codificación de la lengua se establece para la totalidad del recurso léxico. El valor de la lengua se establece para todo el lexicón según se indica en la siguiente instancia del diagrama UML.
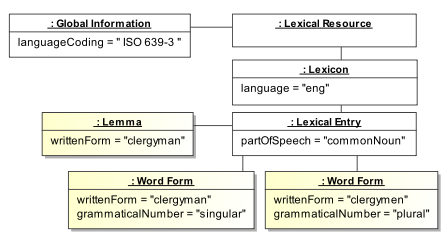
Los elementos Lexical resource, Global Information, Lexicon, Lexical Entry, Lemma, y Word Form definen la estructura del lexicón. Estos elementos se especifican dentro del documento LMF. Por el contrario, languageCoding, language, partOfSpeech, commonNoun, writtenForm, grammaticalNumber, singular, plural son categorías de datos tomadas del Registro de categorías de datos. Estas marcas adornan la estructura. Los valores ISO 639-3, clergyman, clergymen son cadenas simples de caracteres. El valor eng se toma de la lista de lenguas según se define en la norma ISO 639-3.
Con alguna información adicional como dtdVersion y feat, los mismos datos se pueden expresar mediante el siguiente fragmento de XML:
<LexicalResource dtdVersion="14"> <GlobalInformation> <feat att="languageCoding" val="ISO 639-3"/> </GlobalInformation> <Lexicon> <feat att="language" val="eng"/> <LexicalEntry> <feat att="partOfSpeech" val="commonNoun"/> <Lemma> <feat att="writtenForm" val="clergyman"/> </Lemma> <WordForm> <feat att="writtenForm" val="clergyman"/> <feat att="grammaticalNumber" val="singular"/> </WordForm> <WordForm> <feat att="writtenForm" val="clergymen"/> <feat att="grammaticalNumber" val="plural"/> </WordForm> </LexicalEntry> </Lexicon> </LexicalResource>
Vale la pena mencionar que este ejemplo es bastante sencillo. El LMF permite representar descripciones lingüísticas mucho más complejas, pero, en ese caso, el etiquetado XML es mucho más complejo.
Enlaces externos
Páginas web relacionadas
Algunas comunicaciones científicas recientes sobre el LMF
- Gesellschaft für linguistische Datenverarbeitung GLDV-2007/Tubingen: Lexical Markup Framework ISO standard for semantic information in NLP lexicons [2]
- Language Resources and Evaluation LREC-2006/Genoa: Lexical Markup Framework (LMF) [3]
Algunas comunicaciones científicas relacionadas
- Language Resources and Evaluation LREC-2006/Genoa: The relevance of standards for research infrastructures [4]
Véase también
- Morfología lingüística para explicaciones relativas a los paradigmas y la morfosintaxis
- Traducción automática para una presentación de los diferentes tipos de notaciones multilingües (véase la sección Tipos de traducción automática)
- WordNet para una presentación de uno de los lexicones semánticos más famosos en lengua inglesa

Wikimedia foundation. 2010.