- Knn
-
En el método k-nn (K nearest neighbors Fix y Hodges, 1951) es un método de clasificación supervisada (Aprendizaje, estimación basada en un conjunto de entrenamiento y prototipos) que sirve para estimar la función de densidad F(x / Cj) de las predictoras x por cada clase Cj.
Este es un método de clasificación no paramétrico, que estima el valor de la función de densidad de probabilidad o directamente la probabilidad a posteriori de que un elemento x pertenezca a la clase Cj a partir de la información proporcionada por el conjunto de prototipos. En el proceso de aprendizaje no se hace ninguna suposición acerca de la distribución de las variables predictoras.
En el reconocimiento de patrones, el algoritmo k-nn es usado como método de clasificación de objetos (elementos) basado en un entrenamiento mediante ejemplos cercanos en el espacio de los elementos. k-nn es un tipo de "Lazy Learning" (en), donde la función se aproxima solo localmente y todo el cómputo es diferido a la clasificación.
Contenido
Algoritmo
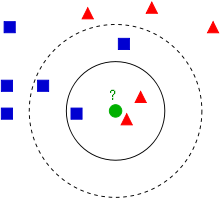 Ejemplo del algoritmo Knn. El ejemplo que se desea clasificar es el circulo verde. Para k = 3 este es clasificado con la clase triángulo, ya que hay solo un cuadrado y 2 triángulos, dentro del circulo que los contiene. Si k = 5 este es clasificado con la clase cuadrado, ya que hay 2 triángulos y 3 cuadrados, dentro del circulo externo.
Ejemplo del algoritmo Knn. El ejemplo que se desea clasificar es el circulo verde. Para k = 3 este es clasificado con la clase triángulo, ya que hay solo un cuadrado y 2 triángulos, dentro del circulo que los contiene. Si k = 5 este es clasificado con la clase cuadrado, ya que hay 2 triángulos y 3 cuadrados, dentro del circulo externo.
Los ejemplos de entrenamiento son vectores en un espacio característico multidimensional, cada ejemplo está descrito en términos de p atributos considerando q clases para la clasificación. Los valores de los atributos del i-esimo ejemplo (donde
 ) se representan por el vector p-dimensional
) se representan por el vector p-dimensional
El espacio es particionado en regiones por localizaciones y etiquetas de los ejemplos de entrenamiento. Un punto en el espacio es asignado a la clase C si esta es la clase más frecuente entre los k ejemplos de entrenamiento más cercano. Generalmente se usa la Distancia euclideana.

La fase de entrenamiento del algoritmo consiste en almacenar los vectores característicos y las etiquetas de las clases de los ejemplos de entrenamiento. En la fase de clasificación, la evaluación del ejemplo (del que no se conoce su clase) es representada por un vector en el espacio característico. Se calcula la distancia entre los vectores almacenados y el nuevo vector, y se seleccionan los k ejemplos más cercanos. El nuevo ejemplo es clasificado con la clase que más se repite en los vectores seleccionados.
Este método supone que los vecinos más cercanos nos dan la mejor clasificación y esto se hace utilizando todos los atributos; el problema de dicha suposición es que es posible que se tengan muchos atributos irrelevantes que dominen sobre la clasificación: dos atributos relevantes perderían peso entre otros veinte irrelevantes.
Para corregir el posible sesgo se puede asignar un peso a las distancias de cada atributo, dándole así mayor importancia a los atributos más relevantes. Otra posibilidad consiste en tratar de determinar o ajustar los pesos con ejemplos conocidos de entrenamiento. Finalmente, antes de asignar pesos es recomendable identificar y eliminar los atributos que se consideran irrelevantes.
En síntesis, el método k-nn se resumen en dos algoritmos:
Algoritmo de entrenamiento
Para cada ejemplo < x,f(x) > ,donde
 , agregar el ejemplo a la estructura representando los ejemplos de aprendizaje.
, agregar el ejemplo a la estructura representando los ejemplos de aprendizaje.Algoritmo de clasificación
Dado un ejemplar xq que debe ser clasificado, sean x1,...,xk los k vecinos más cercanos a xq en los ejemplos de aprendizaje, regresar

donde
δ(a,b) = 1 si a = b; y 0 en cualquier otro caso.
el valor
 devuelto por el algoritmo como un estimador de f(xq) es solo el valor más común de f entre los k vecinos más cercanos a xq. Si elegimos k = 1; entonces el vecino más cercano a xi determina su valor.
devuelto por el algoritmo como un estimador de f(xq) es solo el valor más común de f entre los k vecinos más cercanos a xq. Si elegimos k = 1; entonces el vecino más cercano a xi determina su valor.Elección del k
La mejor elección de k depende fundamentalmente de los datos; generalmente, valores grandes de k reducen el efecto de ruido en la clasificación, pero crean límites entre clases parecidas. Un buen k puede ser seleccionado mediante una optimización de uso. El caso especial en que la clase es predicha para ser la clase más cercana al ejemplo de entrenamiento (cuando k = 1) es llamada Nearest Neighbor Algorithm, Algoritmo del vecino más cercano.
La exactitud de este algoritmo puede ser severamente degradada por la presencia de ruido o características irrelevantes, o si las escalas de características no son consistentes con lo que uno considera importante. Muchas investigaciones y esfuerzos fueron puestos en la selección y crecimiento de características para mejorar las clasificaciones. Particularmente una aproximación en el uso de algoritmos que evolucionan para optimizar características de escalabilidad. Otra aproximación consiste en escalar características por la información mutua de los datos de entrenamiento con las clases de entrenamiento.
Posibles variantes del algoritmo básico
Vecinos más cercanos con distancia ponderada
Se puede ponderar la contribución de cada vecino de acuerdo a la distancia entre él y el ejemplar a ser clasificado xq, dando mayor peso a los vecinos más cercanos. Por ejemplo podemos ponderar el voto de cada vecino de acuerdo al cuadrado inverso de sus distancias

donde

De esta manera se ve que no hay riesgo de permitir a todos los ejemplos entrenamiento contribuir a la clasificación de xq, ya que al ser muy distantes no tendrían peso asociado. La desventaja de considerar todos los ejemplos seria su lenta respuesta (método global). Se quiere siempre tener un método local en el que solo los vecinos más cercanos son considerados.
Esta mejora es muy efectiva en muchos problemas prácticos. Es robusto ante los ruidos de datos y suficientemente efectivo en conjuntos de datos grandes. Se puede ver que al tomar promedios ponderados de los k vecinos más cercanos el algoritmo puede evitar el impacto de ejemplos con ruido aislados.
Categorías:- Algoritmos
- Algoritmos de clasificación

Wikimedia foundation. 2010.