- Pseudocódigo
-
El ciencias de la computación, y análisis numérico el pseudocódigo (o falso lenguaje) es una descripción de un algoritmo de programación informático de alto nivel compacto e informal que utiliza las convenciones estructurales de un lenguaje de programación verdadero, pero que está diseñado para la lectura humana en lugar de la lectura en máquina, y con independencia de cualquier otro lenguaje de programación. Normalmente, el pseudocódigo omite detalles que no son esenciales para la comprensión humana del algoritmo, tales como declaraciones de variables, código específico del sistema y algunas subrutinas. El lenguaje de programación se complementa, donde sea conveniente, con descripciones detalladas en lenguaje natural, o con notación matemática compacta. Se utiliza pseudocódigo pues este es más fácil de entender para las personas que el código de lenguaje de programación convencional, ya que es una descripción eficiente y con un entorno independiente de los principios fundamentales de un algoritmo. Se utiliza comúnmente en los libros de texto y publicaciones científicas que se documentan varios algoritmos, y también en la planificación del desarrollo de programas informáticos, para esbozar la estructura del programa antes de realizar la codificación efectivamente. No existe una sintaxis estándar para el pseudocódigo, aunque los dos programas que manejan pseudocódigo tengan su sintáxis propia. Aunque parecido, el pseudocódigo no debe confundirse con los programas esqueleto que incluyen código ficticio, que pueden ser compilados sin errores. Aunque los diagramas de flujo y UML sean más amplios en el papel, pueden ser considerados como una alternativa gráfica al pseudocódigo.
Contenido
Aplicación
Muchas veces, los libros de texto y publicaciones las científicas relacionadas con la informática y la computación numérica utilizan pseudocódigo en la descripción de algoritmos, de manera que todos los programadores puedan entender, aunque no todos conozcan el mismo lenguaje de programación. Por lo general, en los libros de texto, hay una explicación que acompaña la introducción que explica las convenciones particulares en uso. El nivel de detalle del pseudocódigo puede, en algunos casos, acercarse a la de formalizar los idiomas de propósito general.
Un programador que tiene que aplicar un algoritmo específico, sobre todo uno desfamiliarizado, generalmente comienza con una descripción en pseudocódigo, y luego "traduce" esa descripción en el lenguaje de programación meta y lo modifica para que interactúe correctamente con el resto del programa. Los programadores también pueden iniciar un proyecto describiendo la forma del código en pseudocódigo en el papel antes de escribirlo en su lenguaje de programación, como ocurre en la estructuración de un enfoque de Top-down y Bottom-up arriba hacia abajo.
Características y partes
Las principales características de este lenguaje son:
- Se puede ejecutar en un ordenador (con un IDE como por ejemplo B166ER o PSeInt)
- Es una forma de representación sencilla de utilizar y de manipular.
- Facilita el paso del programa al lenguaje de programación.
- Es independiente del lenguaje de programación que se vaya a utilizar.
- Es un método que facilita la programación y solución al algoritmo del programa.
Todo documento en pseudocódigo debe permitir la descripción de:
- Instrucciones primitivas.
- Instrucciones de proceso....
- Instrucciones de control.
- Instrucciones compuestas.
- Instrucciones de descripción.
Estructura a seguir en su realización:
- Cabecera.
- Programa.
- Módulo.
- Tipos de datos.
- Constantes.
- Variables.
- Cuerpo.
- Inicio.
- Instrucciones.
- Fin.
Definición de datos del pseudocódigo
La definición de datos se da por supuesta, sobre todo en las variables sencillas, si se emplea formaciones: pilas, colas, vectores o registros, se pueden definir en la cabecera del algoritmo, y naturalmente cuando empleemos el pseudocódigo para definir estructuras de datos, esta parte la desarrollaremos adecuadamente.
Funciones y operaciones
Cada autor usa su propio pseudocódigo con sus respectivas convenciones. Por ejemplo, la instrucción "reemplace el valor de la variable x por el valor de la variable y" puede ser representado como:
- asigne a
 el valor de
el valor de 
Las operaciones aritméticas se representan de la forma usual en matemáticas.
Estructuras de control
En la redacción del pseudocódigo se utiliza tres tipos de estructuras de control: las secuenciales, las selectivas y las iterativas.
Estructuras secuenciales
Las instrucciones se siguen en una secuencia fija que normalmente viene dada por el número de renglón. Es decir que las instrucciones se ejecutan de arriba hacia abajo. Las instrucciones se ejecutan dependiendo de la condición dada dentro del algoritmo.
Estructuras selectivas
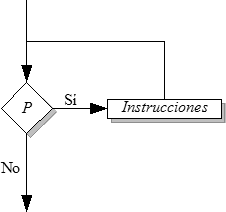
Las instrucciones selectivas representan instrucciones que pueden o no ejecutarse, según el cumplimiento de una condición.
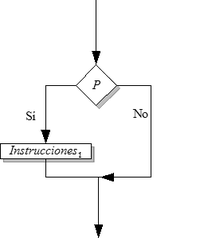 Diagrama de flujo que muestra el funcionamiento de la instrucción condicional.
Diagrama de flujo que muestra el funcionamiento de la instrucción condicional.
La condición es una expresión booleana. Instrucciones es ejecutada sólo si la condición es verdadera.
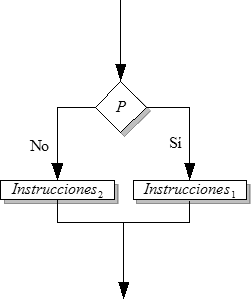
Selectiva doble (alternativa)
La instrucción alternativa realiza una instrucción de dos posibles, según el cumplimiento de una condición.
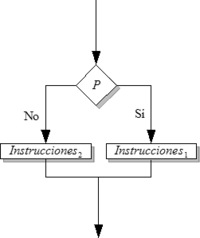 Diagrama de flujo que muestra el funcionamiento de la instrucción condicional.
Diagrama de flujo que muestra el funcionamiento de la instrucción condicional.La condición es una variable booleana o una función reducible a booleana (lógica, Verdadero/Falso). Si esta condición es cierta se ejecuta Instrucciones1, si no es así, entonces se ejecuta Instrucciones2.
Selectiva múltiple
También es común el uso de una selección múltiple que equivaldría a anidar varias funciones de selección.
En este caso hay una serie de condiciones que tienen que ser mutuamente excluyentes, si una de ellas se cumple las demás tienen que ser falsas necesariamente, hay un caso si no que será cierto cuando las demás condiciones sean falsas.
En esta estructura si Condición1 es cierta, entonces se ejecuta sólo Instrucciones1. En general, si Condicióni es verdadera, entonces sólo se ejecuta Instruccionesi
Selectiva múltiple-Casos
Una construcción similar a la anterior (equivalente en algunos casos) es la que se muestra a continuación.
En este caso hay un Indicador es una variable o una función cuyo valor es comparado en cada caso con los valores "Valori", si en algún caso coinciden ambos valores, entonces se ejecutarán las Instruccionesi correspondientes. La sección en otro caso es análoga a la sección si no del ejemplo anterior.
Estructuras iterativas
Las instrucciones iterativas representan la ejecución de instrucciones en más de una vez.
Bucle mientras
El bucle se repite mientras la condición sea cierta, si al llegar por primera vez al bucle mientras la condición es falsa, el cuerpo del bucle no se ejecuta ninguna vez.
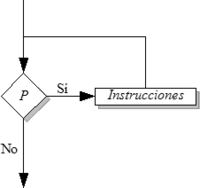 Diagrama de flujo que muestra el funcionamiento de la instrucción mientras
Diagrama de flujo que muestra el funcionamiento de la instrucción mientrasBucle repetir
Existen otras variantes que se derivan a partir de la anterior. La estructura de control repetir se utiliza cuando es necesario que el cuerpo del bucle se ejecuten al menos una vez y hasta que se cumpla la condición:
La estructura anterior equivaldría a escribir:
Bucle para
Una estructura de control muy común es el ciclo para, la cual se usa cuando se desea iterar un número conocido de veces, empleando como índice una variable que se incrementa (o decrementa):
la cual se define como:
Bucle para cada
Por último, también es común usar la estructura de control para cada. Esta sentencia se usa cuando se tiene una lista o un conjunto L y se quiere iterar por cada uno de sus elementos:
Si asumimos que los elementos de L son
 , entonces esta sentencia equivaldría a:
, entonces esta sentencia equivaldría a:Que es lo mismo que:
Sin embargo, en la práctica existen mejores formas de implementar esta instrucción dependiendo del problema.
Es importante recalcar que el pseudocódigo no es un lenguaje estandarizado. Eso significa que diferentes autores podrían dar otras estructuras de control o bien usar estas mismas estructuras, pero con una notación diferente. Sin embargo, las funciones matemáticas y lógicas toman el significado usual que tienen en matemática y lógica, con las mismas expresiones.
El anidamiento
Cualquier instrucción puede ser sustituida por una estructura de control. El siguiente ejemplo muestra el pseudocódigo del ordenamiento de burbuja, que tiene varias estructuras anidadas. Este algoritmo ordena de menor a mayor los elementos de una lista L.

En general, las estructuras anidadas se muestran indentadas, para hacer más sencilla su identificación a simple vista. En el ejemplo, además de la indentación, se ha conectado con flechas los pares de delimitadores de cada nivel de anidamiento.
Desarrollo de algoritmos
Con este pseudocódigo se puede desarrollar cualquier algoritmo que:
- Tenga un único punto de inicio.
- Tenga un número finito de posibles puntos de término.
- Haya un número finito de caminos, entre el punto de inicio y los posibles puntos de término.
Funciones y procedimientos
Muchas personas prefieren distinguir entre funciones y procedimientos. Una función, al igual que una función matemática, recibe uno o varios valores de entrada y regresa una salida mientras que un procedimiento recibe una entrada y no genera ninguna salida aunque en algún caso podría devolver resultados a través de sus parámetros de entrada si estos se han declarado por referencia (ver formas de pasar argumentos a una función o procedimiento).
En ambos casos es necesario dejar en claro cuáles son las entradas para el algoritmo, esto se hace comúnmente colocando estos valores entre paréntesis al principio o bien declarándolo explícitamente con un enunciado. En el caso de las funciones, es necesario colocar una palabra como regresar o devolver para indicar cuál es la salida generada por el algoritmo. Por ejemplo, el pseudocódigo de una función que permite calcular an (un número a elevado a potencia n).
Un ejemplo de procedimiento seria el algoritmo de Ordenamiento de burbuja, por el que partiendo de una lista de valores estos se ordenan, nótese que en un procedimiento, no se calcula el valor de una función, sino que se realiza una acción, en este caso ordenar la lista.
Ventajas del pseudocódigo sobre los diagramas de flujo
- Ocupan mucho menos espacio en el desarrollo del problema.
- Permite representar de forma fácil operaciones repetitivas complejas.
- Es más sencilla la tarea de pasar de pseudocódigo a un lenguaje de programación formal.
- Si se siguen las reglas de identación se puede observar claramente los niveles en la estructura del programa.
- En los procesos de aprendizaje de los alumnos de programación, éstos están más cerca del paso siguiente (codificación en un lenguaje determinado, que los que se inician en esto con la modalidad Diagramas de Flujo).
- Mejora la claridad de la solución de un problema.
Bibliografía
- Peña Marí, Ricardo (2005) (en español). Diseño de programas: formalismo y abstracción (3 edición). Pearson Alhambra. pp. 488. ISBN 978-84-205-4191-4.
- (en español) Pseudocódigos y programación estructurada (1 edición). Centro Técnico Europeo de Enseñanzas Profesionales. 2 de 1997. ISBN 978-84-8199-065-2.
- Brassard, Gilles; Bratley, Paul (1996) (en español). Algorítmica: concepción y análisis. Peña Mari, Ricardo Tr. (1 edición). Masson, S.A.. pp. 384. ISBN 978-84-458-0535-0.
- Rodeira, ed (6 de 1994) (en Gallego). Pseudocódigos e programación estructurada (1 edición). ISBN 978-84-8116-287-5.
- Edebé, ed (8 de 1993) (en español). Pseudocódigos y programación estructurada (1 edición). ISBN 978-84-236-3126-1.
Véase también
Enlaces externos
Categorías:- Programación
- Herramientas de programación
- Diseño de software



































































Wikimedia foundation. 2010.