- Familia exponencial
-
Familia exponencial
En probabilidad y estadística, la familia exponencial es una clase de distribuciones de probabilidad cuya formulación matemática puede expresarse de la manera que se especifica debajo. Esta formulación confiere a las distribuciones de esta familia una serie de propiedades algebraicas y estadísticas muy convenientes.
El concepto de la familia exponencial fue introducido por[1] E. J. G. Pitman,[2] G. Darmois,[3] and B. O. Koopman[4] en 1935.
Contenido
Definición
A continuación se ofrece una serie de definiciones de la familia exponencial con un grado creciente de generalidad y abstracción.
Parámetro escalar
La familia exponencial de parámetro escalar es un conjunto de funciones de distribución cuya función de densidad puede expresarse de la forma
donde T(x), h(x), η(θ) y A(θ) son funciones conocidas.
A θ se lo denomina parámetro de la familia.
A menudo, x es un vector de observaciones. En tal caso, T(x) es una función real sobre el espacio de posibles valores de x.
Si η(θ) = θ se dice que la familia exponencial está expresada en su forma canónica. Redefiniendo η = η(θ), es posible expresar una familia exponencial en su forma canónica. De todos modos, la forma canónica no es única dado que η(θ) puede aparecer multiplicado por una constante no nula y T(x), a su vez, multiplicada por su inversa.
Parámetro vectorial
La definición anterior puede extenderse al caso de un parámetro vectorial
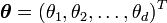 . En tal caso, se dice que una familia de distribuciones pertenece a la familia exponencial cuando su función de densidad puede expresarse de la forma
. En tal caso, se dice que una familia de distribuciones pertenece a la familia exponencial cuando su función de densidad puede expresarse de la formaComo en el caso escalar, se dice que está en forma canónica cuando
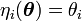 para todo i.
para todo i.Se dice que la familia exponencial está curvada cuando la dimensión de
es menor que la del vector 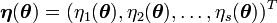 , es decir, cuando la dimensión del vector de parámetros es menor que el número de funciones del vector de parámetros en la representación anterior.
, es decir, cuando la dimensión del vector de parámetros es menor que el número de funciones del vector de parámetros en la representación anterior.Formulación de acuerdo con la teoría de la medida
Supóngase que H es una función real de variable real no decreciente y que H(x) tiende a cero cuando x tiende a −∞. Entonces, la integral de Lebesgue–Stieltjes con respecto a dH(x) son integrales con respecto a la medida de referencia de la familia exponencial generada por H.
Un miembro de tal familia exponencial tiene función de distribución
Si F es una función de distribución continua que tiene densidad, se puede escribir dF(x) = f(x) dx.
H(x) es entonces el integrador de Lebesgue–Stieltjes para la medida de referencia. Cuando la medida de referencia es finita puede ser normalizada y H es una función de distribución. Si F es continua y tiene una densidad, lo mismo sucede con H; entonces se puede escribir dH(x) = h(x) dx. Si F es discreta, entonces H es una función escalonada is a step function (con escalones en el soporte de F).
Interpretación
En las definiciones anteriores, las funciones T(x), η(θ) y A(θ) parecen haber sido definidas arbitrariamente. Sin embargo, desempeñan un papel particular en la función de distribución.
- T(x) es un estimador suficiente de la distribución. Así, las familias exponenciales cuentan con un estimador suficiente coya dimensión es igual al del número de parámetros estimables.
- η es el llamado parámetro natural. El conjunto de sus valores para los que fX(x;θ) es finito recibe el nombre de espacio del parámetro natural. Puede demostrarse que dicho espacio es siempre convexo.
- A(θ) es un factor de normalización gracias al cual fX(x;θ) es una función de distribución. La función A tiene gran importancia por sí misma dado que en los casos en lo que la medida de referencia dH(x) es una medida de probabilidad, A es la función generadora de la distribución del estadístico suficiente T(X) cuando la distribución de X es dH(x).
En particular, para el caso escalar y cuando la familia exponencial está expresada en su forma canónica, se tiene que
Derivando con respecto a θ, se obtiene
e, integrando dicha expresión con respecto a x, (y permutando la integral y la derivada) se llega a que
es decir,
Tomando derivadas sucesivas respecto a θ puede deducirse que la varianza de T(x) es la derivada segunda de A(θ), etc.
Ejemplos
Muchas de las familias de funciones de distribución pertenecen a la exponencial. Por ejemplo, la normal, la exponencial, la gamma, la chi-cuadrado, la beta, la Weibull (si el parámetro de forma es conocido), la distribución de Dirichlet, la de Bernoulli, la binomial, la multinomial, la de Poisson, la distribución binomial negativa y la geométrica. También lo es la de Pareto cuando el límite inferior del soporte está fijo.
Sin embargo, las distribuciones [[distribución uniforme|uniforme[[y de Cauchy no forman parte de la familia exponencial. La de Weibull no es de la familia exponencial a no ser que el parámetro de forma sea conocido. Y la de Laplace tampoco lo es a no ser que su media sea conocida e igual a cero.
A continuación se ofrencen algunos ejemplos detallados de la respresentación de algunas familias de funciones de densidad de acuerdo con el formalismo de las familias exponenciales.
Distribución normal de varianza unitaria y media desconocida
En tal caso, la función de densidad es
Pertenece a la familia exponencial como puede apreciarse identificando
Distribución normal con media y varianza desconocidas
En tal caso, la función de densidad es
y pueden definirse
Distribución binomial
Como ejemplo de una familia exponencial discreta puede considerarse la binomial. Su función de probabilidad es
que puede escribirse también como
De ahí que esté dentro de la familia exponencial con parámetro natural
Importancia en estadística
Estimación clásica: suficiencia
De acuerdo con el teorema de Pitman-Koopman-Darmois, dentro de las familias cuyo dominio no varía con el parámetro que se quiere estimar, sólo existe un estadístico suficiente cuya dimensión permanece constante al aumentar el tamaño muestral dentro de las familias exponenciales.
Estimación bayesiana y distribuciones conjugadas
Cuando la función de verosimilitud pertenece a la familia exponencial, siempre existe una distribución a priori conjugada que, ademas, a menudo, pertenece a la familia exponencial también. Una distribuición a priori conjugada π para el parámetro η de la familia exponencial es
donde
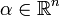 y β > 0 son hiperparámetros.
y β > 0 son hiperparámetros.Tests uniformemente más potente
La familia exponencial uniparamétrica es una función monótonamente creciente de su estadístico suficiente T(x) siempre que η(θ) no sea decreciente. :) Como consecuencia, existe un test uniformemente más potente para verificar la hipótesis H0: θ ≥ θ0 contra H1: θ < θ0.
Existencia del estimador de máxima verosimilitud
Aunque el estimador de máxima verosimilitud de una familia de distribuciones no tiene por qué existir o ser único, la situación es distinta dentro de la familia exponencial. De hecho, el logaritmo de la función de verosimilitud es necesariamente cóncavo.
Referencias
- ↑ Andersen, Erling (September de 1970). «Sufficiency and Exponential Families for Discrete Sample Spaces» Journal of the American Statistical Association. Vol. 65. n.º 331. pp. 1248–1255.
- ↑ Pitman, E. (1936). «Sufficient statistics and intrinsic accuracy» Proc. Camb. phil. Soc.. Vol. 32. pp. 567–579.
- ↑ Darmois, G. (1935). «Sur les lois de probabilites a estimation exhaustive» C.R. Acad. sci. Paris. Vol. 200. pp. 1265–1266.
- ↑ Koopman, B (1936). «On distribution admitting a sufficient statistic» Trans. Amer. math. Soc.. Vol. 39. pp. 399–409.
Categoría: Distribuciones de probabilidad
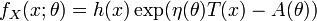
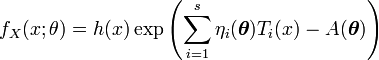
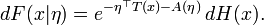
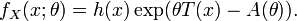
![\frac{d}{d\theta} f_X(x; \theta) = [T(x) - A^\prime (\theta )] f_X(x; \theta) \,\!](/pictures/eswiki/54/60161143cf765621eddbe73dd53f0e0f.png)
![0 = \frac{d}{d\theta} \int f_X(x; \theta) = \int [T(x) - A^\prime (\theta )] f_X(x; \theta) \,\!,](/pictures/eswiki/54/62749439e1af1df03ec65c71e46b23a9.png)
![A^\prime (\theta ) = \int A^\prime (\theta ) f_X(x; \theta) = \int T(x) f_X(x; \theta) = E_\theta[T(x)] \,\!.](/pictures/eswiki/49/1d79ea9110689232c4ce06a32d9571b4.png)
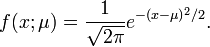
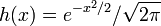
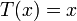
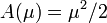
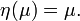
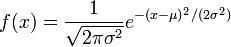
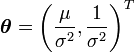
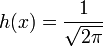
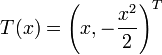
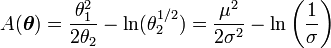
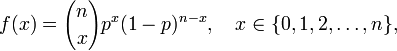
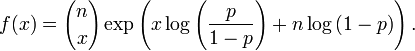
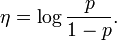
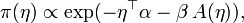
Wikimedia foundation. 2010.